郑州网络公司www
xw0371
com郑州网站建设www
youhua178
com网络爬行蜘蛛定义及原理讲解当“蜘蛛”程序出现时,现代意义上的搜索引擎才初露端倪
它实际上是一种电脑“机器人”(ComputerRobot),电脑“机器人”是指某个能以人类无法达到的速度不间断地执行某项任务的软件程序
由于专门用于检索信息的“机器人”程序就象蜘蛛一样在网络间爬来爬去,反反复复,不知疲倦
所以,搜索引擎的“机器人”程序就被称为“蜘蛛”程序
网络蜘蛛什么是网络蜘蛛呢
网络蜘蛛即WebSpider,是一个很形象的名字
把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛
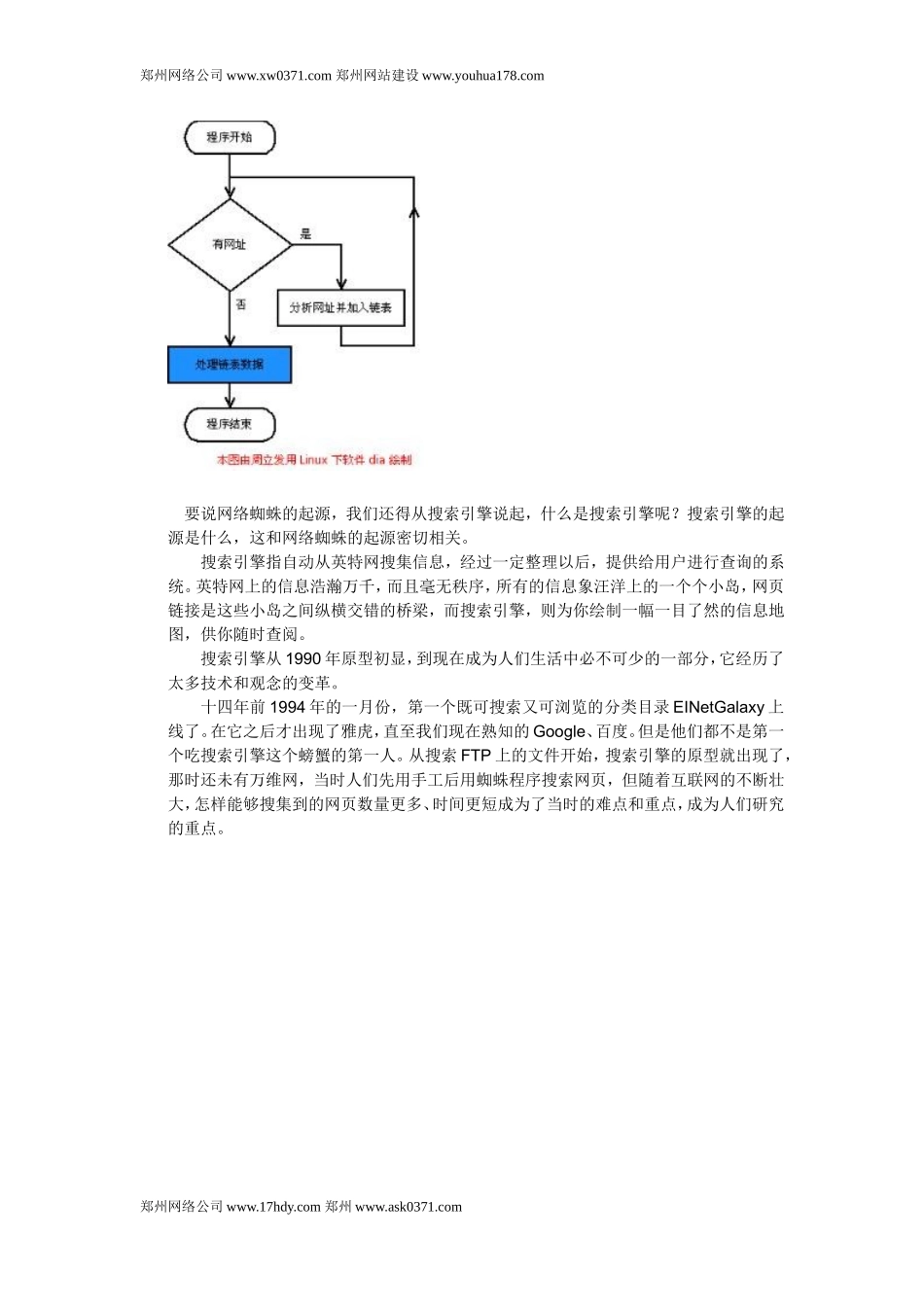
网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止
如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来
这样看来,网络蜘蛛就是一个爬行程序,一个抓取网页的程序
起源发展郑州网络公司www
com郑州www
ask0371
com郑州网络公司www
xw0371
com郑州网站建设www
youhua178
com要说网络蜘蛛的起源,我们还得从搜索引擎说起,什么是搜索引擎呢
搜索引擎的起源是什么,这和网络蜘蛛的起源密切相关
搜索引擎指自动从英特网搜集信息,经过一定整理以后,提供给用户进行查询的系统
英特网上的信息浩瀚万千,而且毫无秩序,所有的信息象汪洋上的一个个小岛,网页链接是这些小岛之间纵横交错的桥梁,而搜索引擎,则为你绘制一幅一目了然的信息地图,供你随时查阅
搜索引擎从1990年原型初显,到现在成为人们生活中必不可少的一部分,它经历了太多技术和观念的变革
十四年前1994年的一月份,第一个既可