浙江大学远程教育学院 《数据挖掘》课程作业 姓名: 吴金翔 学 号: 713070244001 年级: 1 3 春信息管理 学习中心: 余杭 ————————————————————————————— 第一章 引言 一、填空题 (1)数据库中的知识挖掘(KDD)包括以下七个步骤:数据清理 、 数据集成 、 数据选择 、 数据变换 、 数据挖掘 、模式评估 和 知识表示 (2) 数据挖掘的性能问题主要包括: 算法的效率 、 可扩展性 和 并行处理 (3) 当前的数据挖掘研究中,最主要的三个研究方向是: 统计学 、 数据路技术 和 机器学习 (4) 孤立点是指: 一些与数据的一般行为或模型不一致的孤立数据 二、简答题 (1)什么是数据挖掘
答:数据挖掘指的是从大量的数据中挖掘出那些令人感兴趣的,有用的,隐含的,先前未知的和可能有用的模式或知识
(2)一个典型的数据挖掘系统应该包括哪些组成部分
答:1,数据库、数据仓库或其他信息库;2,数据库或数据仓库服务器;3,知识库;4,数据挖掘引擎;5,模式评估模块;6
图形用户界面
(3)Web 挖掘包括哪些步骤
答:数据清理(可能有占全过程的 60%的工作量);将数据存入数据仓库;建立数据立方体;选择用来进行数据挖掘的数据;数据挖掘(选择适当的算法来找到感兴趣的模式);展现挖掘结果;将模式或者知识应用或者存入知识库
(4)请列举数据挖掘应用常见的数据源
(或者说,我们都在什么样的数据上进行数据挖掘) 答:常见的数据源包括关系数据路、数据仓库、事务数据库和高举数据库系统和信息库
其中国际数据库系统和信息库包括:空间数据库、时间数据库和时间序列数据库、流数据、多媒体数据库、面向对象数据库和对象关系数据库、异种数据库和遗产数据库、文本数据库和万维网等
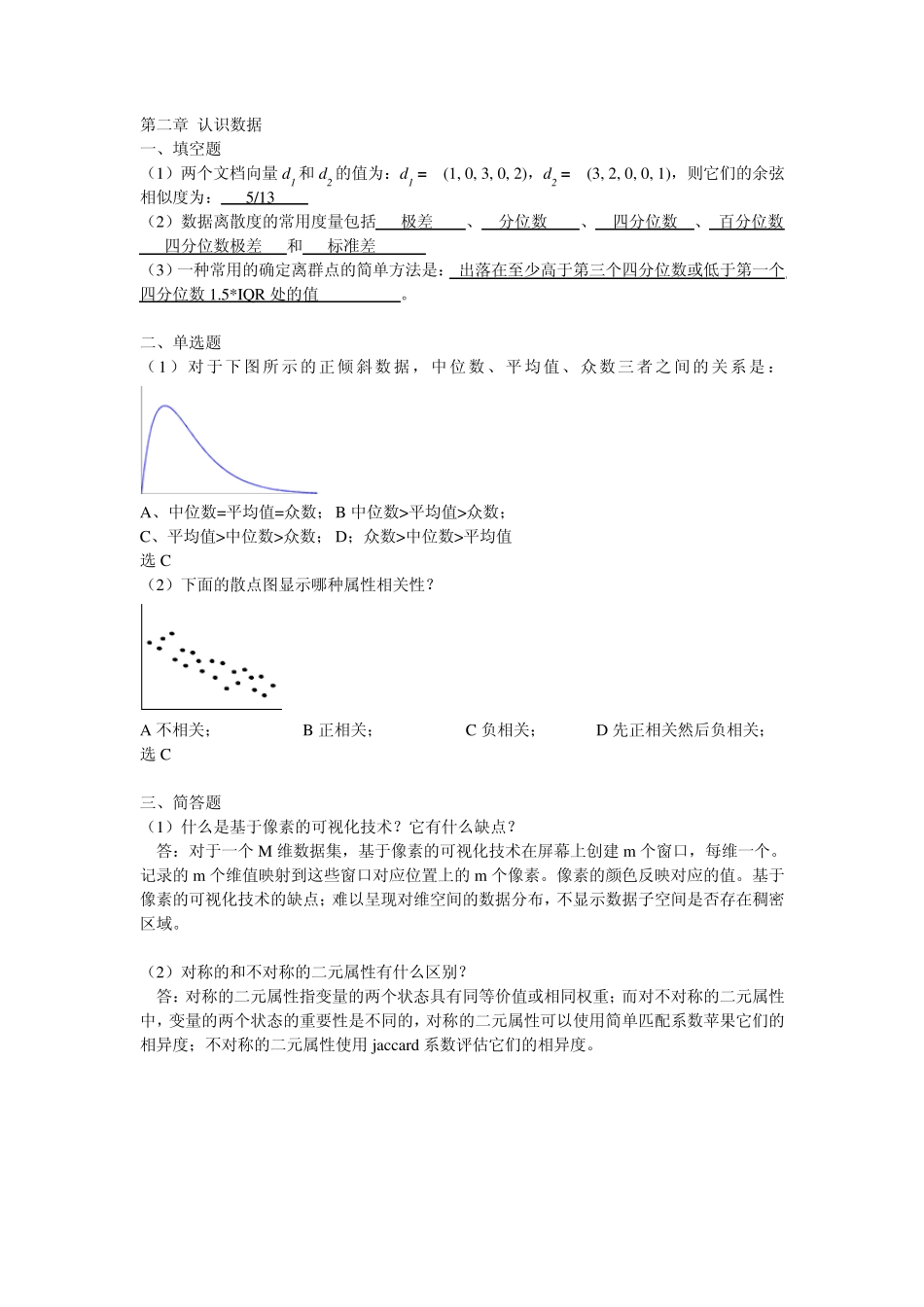
第二章 认识数据 一、填空题 (1)两个文档向量 d 1 和 d 2 的值为