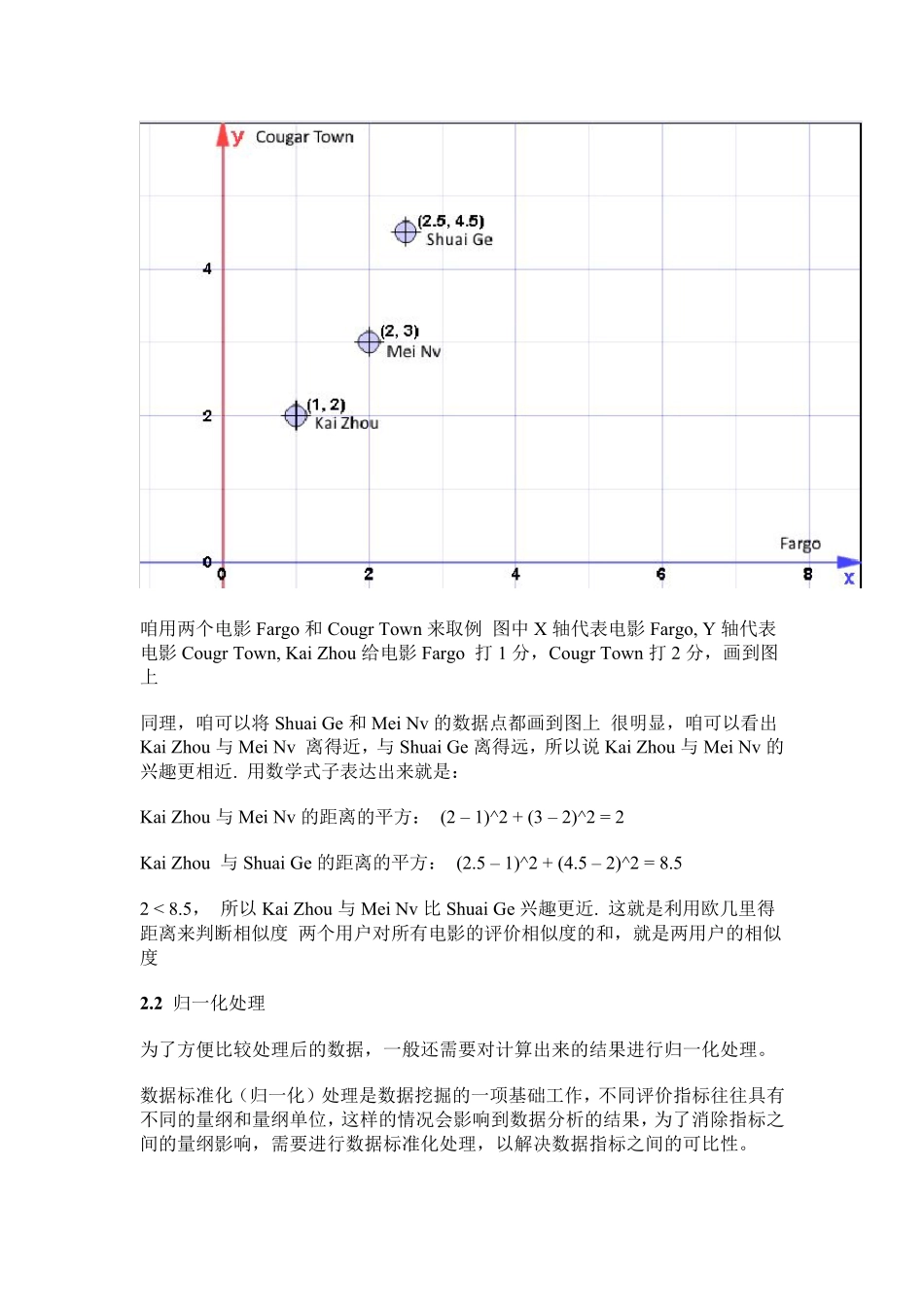
似乎咱的产品七,八年前就想做个推荐系统的,就是类似根据用户的喜好,自动的找到用户喜欢的电影或者节目,给用户做推荐。可是这么多年过去了,不知道是领导忘记了还是怎么了,连个影子还没见到。而市场上各种产品的都有了推荐系统了。比如常见的各种购物网站京东,亚马逊,淘宝之类的商品推荐,视频网站优酷的的类似影片推荐,豆瓣音乐的音乐推荐… …一个好的推荐系统推荐的精度必然很高,能够真的发现用户的潜在需求或喜好,提高购物网詀的销量,让视频网站发现用户喜欢的收费电影…可是要实现一个高精度的推荐系统不是那么容易的,netflix 曾经悬赏高额奖金寻找能给其推荐系统的精确度提高 10%的人,可见各个公司对推荐系统的重视和一个好的推荐系统确实能带来经济效益。下面咱以电影电视的推荐系统为例,一步一步的来实现一个简单的推荐系统吧,由于比较简单,整个推荐系统源码不到100 行,大概 70-80 行吧,应该很容易掌握。 为了快速开发原型,咱采用Python 代码来演示1. 推荐系统的第一步,需要想办法收集信息不同的业务,不同的推荐系统需要收集的信息不一样 针对咱要做的电影推荐,自然是每个用户对自己看过的电影的评价了,如下图所示:Kai Zhou 对 Friends 打分是4 分,对 Bedtime Stories 打分是3 分,没有对 RoboCop打分 Shuai Ge 没有对 Friends 打分,对 Bedtime Stories 打分是3.5 分 … …为简单,咱将此数据存成 csv 文件,形成一个二维的矩阵,假设存在 D:\train.csv,数据如下:Name,Friends,Bedtime Stories,Dawn of the Planet of theApes,RoboCop,Fargo,Cougar TownKai Zhou,4,3,5,,1,2Shuai Ge,,3.5,3,4,2.5,4.5MeiNv,3,4,2,3,2,3xiaoxianrou,2.5,3.5,3,3.5,2.5,3fengzhi,3,4,,5,3.5,3meinv,,4.5,,4,1,mincat,3,3.5,1.5,5,3.5,3alex,2.5,3,,3.5,,4先从 csv 文件中加载二维矩阵,代码如下:def load_matrix():matrix = {}f = open("d:\\train.csv")columns = f.readline().split(',')for line in f:scores = line.split(',')for i in range(len(scores))[1:]:matrix[(scores[0], columns[i])] = scores[i].strip("\n")return matrixmatrix = load_matrix()print "matrix:", matrixload_matrix()解析csv 文件,返回一个dictionary, 该dictionary 以(行名,列名)为索引数据有了,下面咱就正式开始干活了,推荐系统要干些什么呢?咱以电影推荐来说,...