聚类分析 (一)概述 聚类分析,相当于“物以类聚”,用于对事物的类别面貌尚不清楚,甚至在事前连总共有几类都不能确定的情况下对数据进行分类
而判别分析,必须事先知道各种判别的类型和数目,并且要有一批来自各判别类型的样本,才能建立判别函数来对未知属性的样本进行判别和归类
聚类分析是把分类对象按一定规则分成组或类,这些组或类不是事先给定的而是根据数据特征而定的
在同类的对象在某种意义上倾向于彼此相似,而在不同类里的这些对象倾向于不相似
根据这种相似性的不同定义,聚类分析也有不同的方法
聚类分析分为:对样品的聚类,对变量的聚类
样品聚类:其统计指标是类与类之间距离,把每一个样品看成空间中的一个点,用某种原则规定类与类之间的距离,将距离近的点聚合成一类,距离远的点聚合成另一类
变量聚类:其统计指标是相似系数,将比较相似的变量归为一类,而把不怎么相似的变量归为另一类,用它可以把变量的亲疏关系直观地表示出来
(二)原理 一、距离和相似系数 1
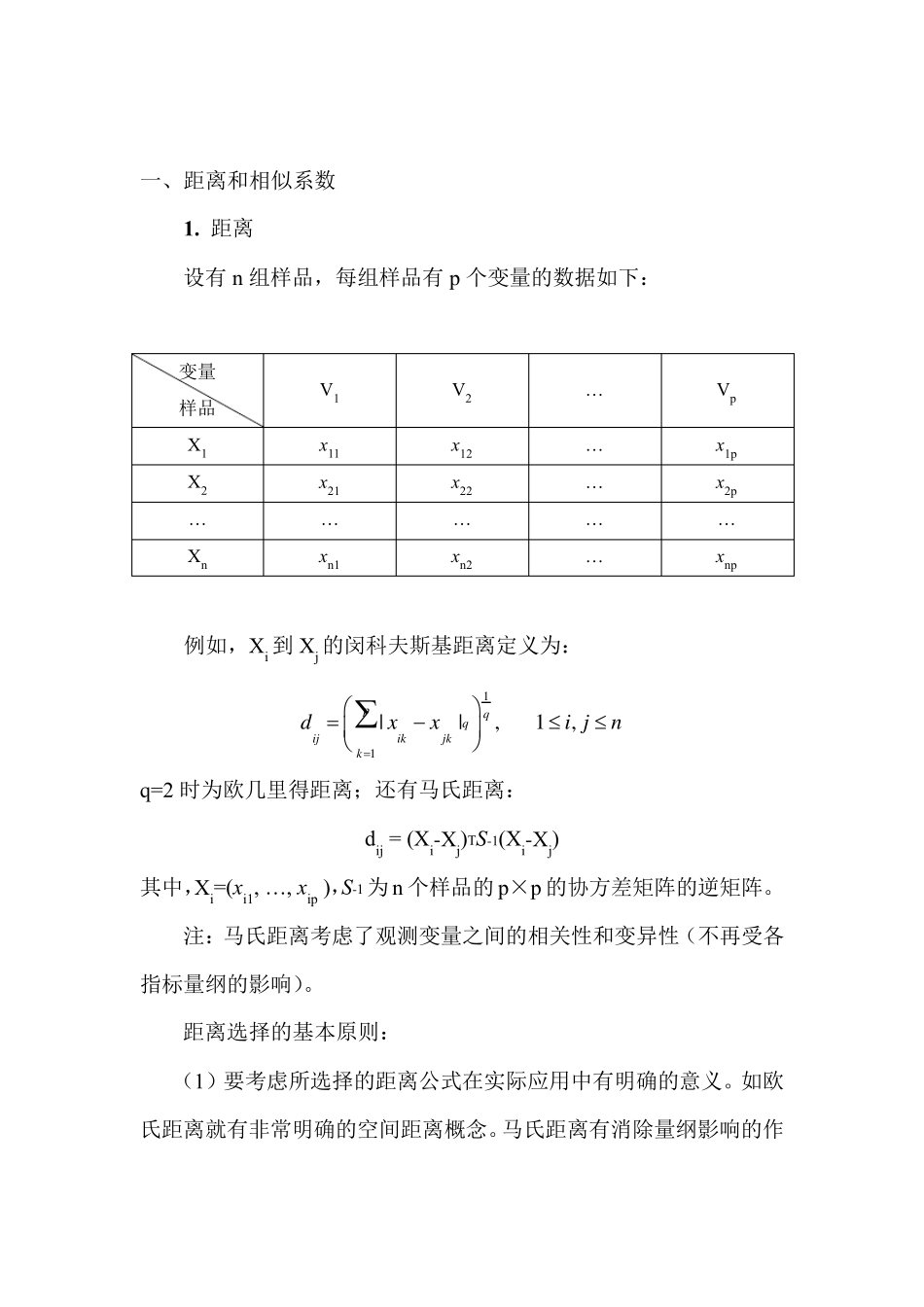
距离 设有n 组样品,每组样品有p 个变量的数据如下: 变量 样品 V1 V2 … Vp X1 x11 x12 … x1p X2 x21 x22 … x2p … … … … … Xn xn1 xn2 … xnp 例如,Xi 到Xj 的闵科夫斯基距离定义为: 11||, 1,pqqijikjkkdxxi jn q=2 时为欧几里得距离;还有马氏距离: dij = (Xi-Xj)TS-1(Xi-Xj) 其中,Xi=(xi1, … , xip ),S-1为n 个样品的p×p 的协方差矩阵的逆矩阵
注:马氏距离考虑了观测变量之间的相关性和变异性(不再受各指标量纲的影响)
距离选择的基本原则: (1)要考虑所选择的距离公式在实际应用中有明确的意义
如欧氏距离就有非常明确的空间距离概念
马氏距离有消除量纲影响