决策树程序实验 众所周知,数据库技术从20 世纪80 年代开始,已经得到广泛的普及和应用
随着数据库容量的膨胀,特别是数据仓库以及web 等新型数据源的日益普及,人们面临的主要问题不再是缺乏足够的信息可以使用,而是面对浩瀚的数据海洋如何有效地利用这些数据
从数据中生成分类器的一个特别有效的方法是生成一个决策树(Decision Tree)
决策树表示方法是应用最广泛的逻辑方法之一,它从一组无次序、无规则的事例中推理出决策树表示形式的分类规则
决策树分类方法采用自顶向下的递归方式,在决策树的内部结点进行属性值的比较并根据不同的属性值判断从该结点向下的分支,在决策树的叶结点得到结论
所以从决策树的根到叶结点的一条路径就对应着一条合取规则,整棵决策树就对应着一组析取表达式规则
决策树是应用非常广泛的分类方法,目前有多 种 决策树方法,如ID3、CN2、SLIQ、SPRINT 等
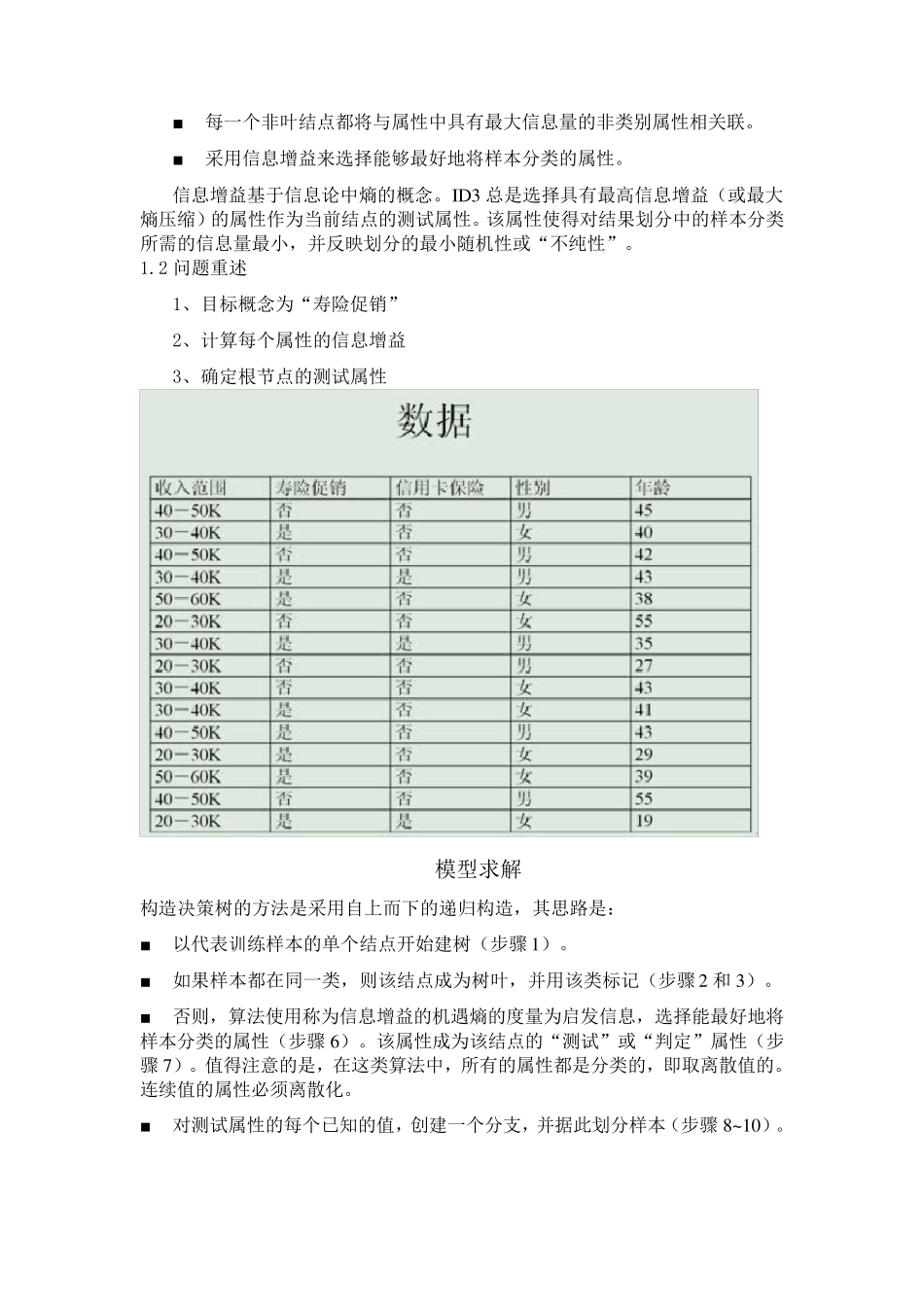
一、问题描 述 1
1 相 关 信息 决策树是一个类似 于 流 程图 的树结构 ,其 中每 个内部结点表示在一个属性上的测 试 ,每 个分支代表一个测 试 输 入 ,而每 个树叶结点代表类或 类分布
数的最顶层 结点是根结点
一棵典 型的决策树如图 1 所示
它表示概 念 buys_computer,它预 测 顾 客 是否 可能 购 买 计 算 机
内部结点用矩 形表示,而树叶结点用椭 圆 表示
为 了 对未 知的样 本 分类,样 本 的属性值在决策树上 测 试
决策树从根到叶结点的一条路径就对应着一条合取规则,因 此 决策树容易 转 化 成分类规则
图 1 ID3 算 法: ■ 决策树中每 一个非叶结点对应着一个非类别属性,树枝 代表这个属性的值
一个叶结点代表从树根到叶结点之间 的路径对应的记 录 所属的类别属性值
■ 每一个非叶结点都将与属性中具有最大信息量的非类别属性相关联