提高 Tesseract-OCR 识别精度的方法1
0 Tesseract-OCR简介OCR(Optical Character Recognition 光学字符识别) 技术,是指电子设备 (例如扫描仪或数码相机) 检查纸上打印的字符, 通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程
Tesseract的 OCR引擎最先由 HP实验室于 1985 年开始研发,至 1995 年时已经成为 OCR业内最准确的三款识别引擎之一
然而,HP不久便决定放弃OCR业务, Tesseract也从此尘封
数年以后,HP意识到,与其将 Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生-- 2005 年, Tesseract由美国内华达州信息技术研究所获得,并求诸于 Google 对 Tesseract进行改进、消除 Bug、优化工作
Tesseract目前已作为开源项目发布在Google Project,其最新版本 3
0 已经支持中文 OCR
1 Tesseract-OCR的安装及使用说明1
Tesseract-OCR的安装过程下载 tesseract-ocr-setup-3
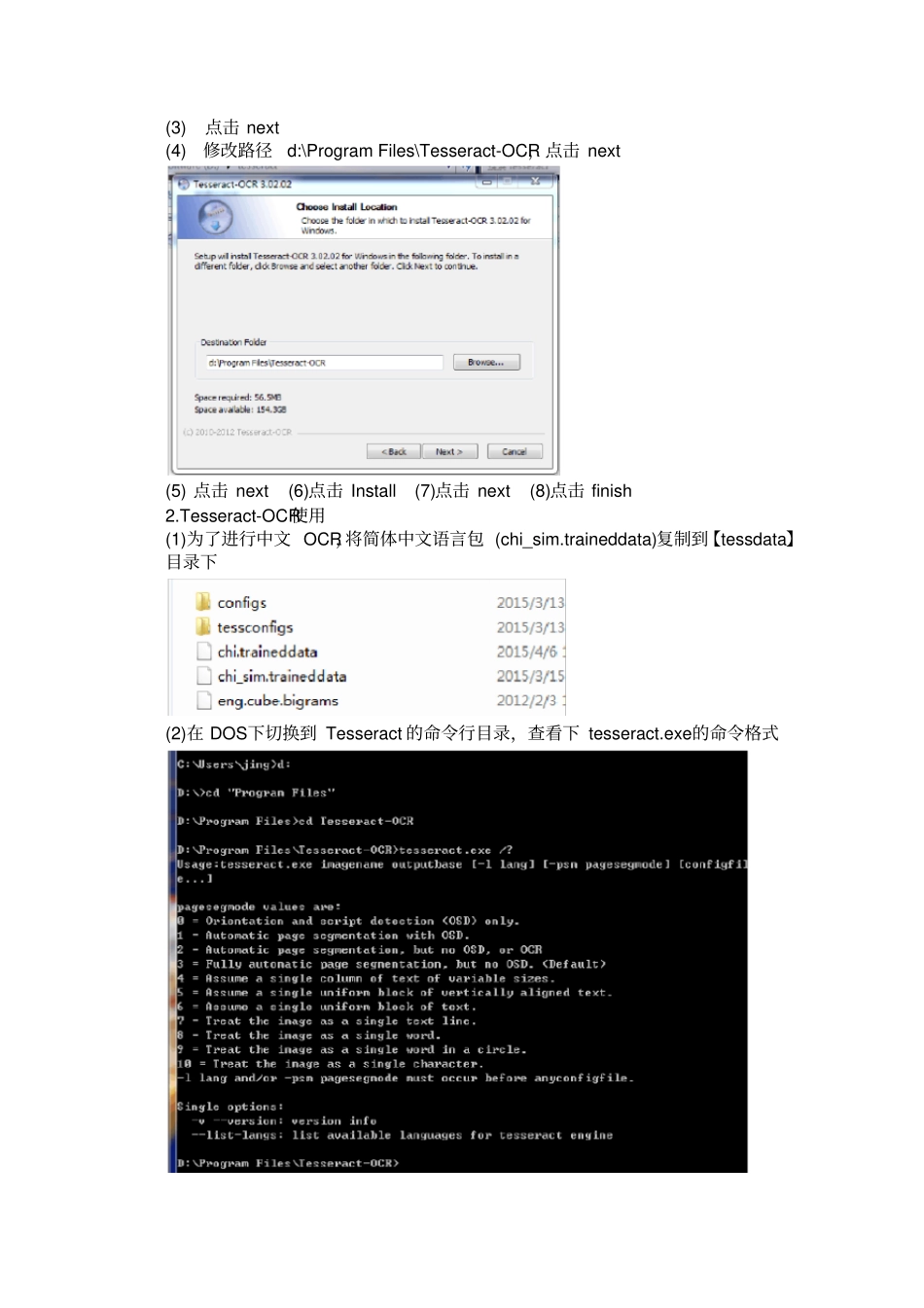
exe 进行安装(1) click next (2) 选中 I accept the terms of License Agreement,点击 next (3)点击 next (4)修改路径d:\Program Files\Tesseract-OCR,点击 next (5) 点击 next (6)点击 Install (7)点击 next (8)点击 finish 2
Tesseract-OCR使用(1)为了进行中文 OCR,将简体中文语言包 (chi_sim
traineddata)复制到【tessdata】目录下(2)在 DOS下切换到 Tesse