大数据技术实验报告 大数据技术实验一 Hadoop 大数据平台安装实验 1 实验目的 在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux 命令的基础上搭建Hadoop(HDFS、MapReduce、HBase、Hiv e)、Spark、Scala、Storm、Kafka、JDK、My SQL、ZooKeeper 等的大数据采集、处理分析技术环境
2 实验环境 个人笔记本电脑Win10、 Oracle VM VirtualBox 5
44、 CentOS-7-x 86_64-Minimal-1511
iso 3 实验步骤 首先安装虚拟机管理程序,然后创建三台虚拟服务器,最后在虚拟服务器上搭建以 Hadoop 集群为核心的大数据平台
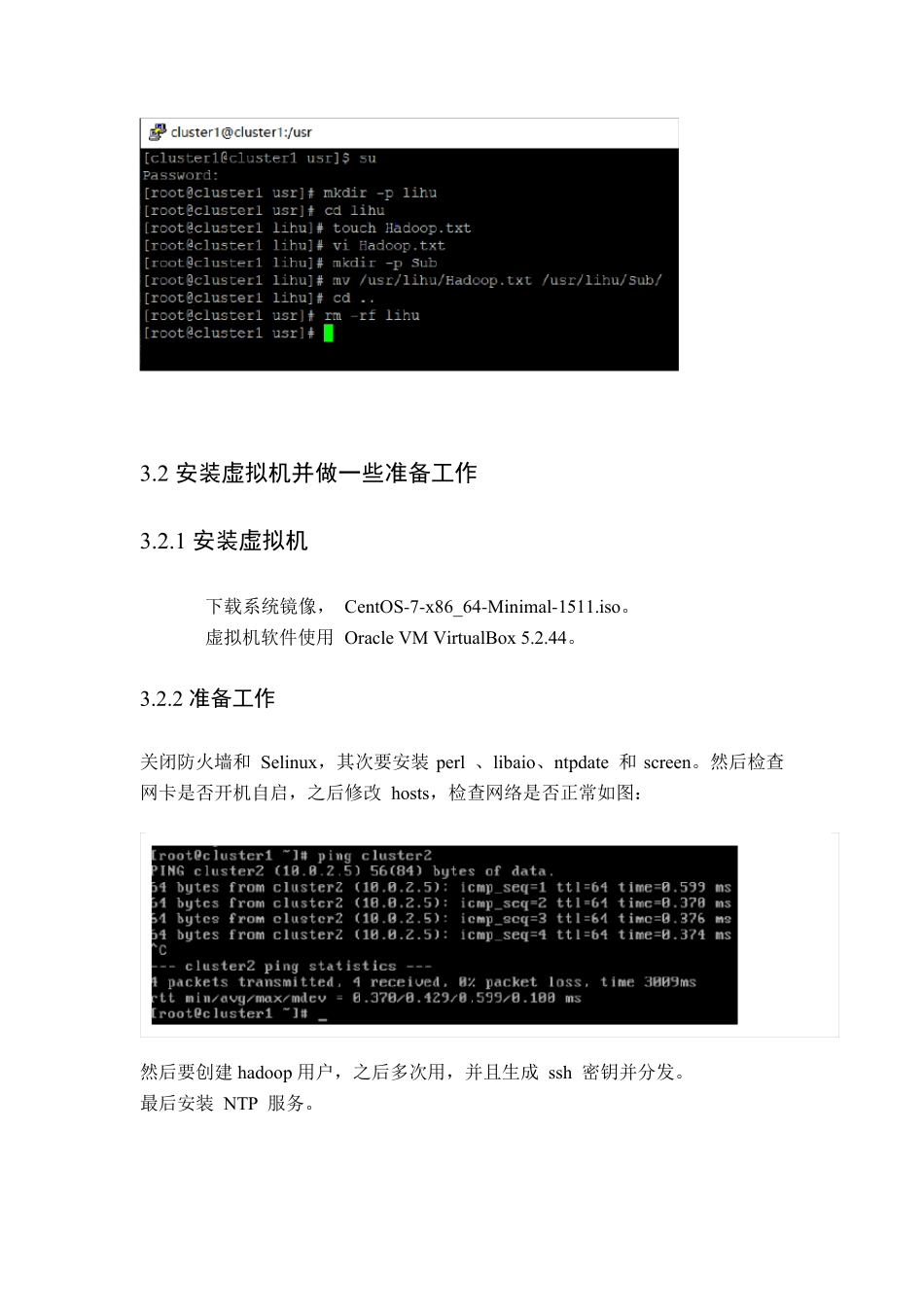
1 快速热身,熟悉并操作下列Linux 命令 ·创建一个初始文件夹,以自己的姓名(英文)命名;进入该文件夹,在这个文件夹下创建一个文件,命名为Hadoop
·查看这个文件夹下的文件列表
·在Hadoop
txt 中写入“Hello Hadoop
”,并保存 ·在该文件夹中创建子文件夹”Sub”,随后将Hadoop
txt 文件移动到子文件夹中
·递归的删除整个初始文件夹
2 安装虚拟机并做一些准备工作 3
1 安装虚拟机 下载系统镜像, CentOS-7-x 86_64-Minimal-1511
虚拟机软件使用 Oracle VM VirtualBox 5
2 准备工作 关闭防火墙和 Selinux ,其次要安装perl 、libaio、ntpdate 和screen
然后检查网卡是否开机自启,之后修改 hosts,检查网络是否正常如图: 然后要创建hadoop 用户,之后多次用,并且生成 ssh 密钥并分发
最后安装 NTP 服务