DW&DM课程实验报告 班级:信管 1 1 -1 姓名:*** 学号:************ 一、 实验目的 验证 二、 实验内容 (一) 聚类分析 (1)数据准备 1
数据文件格式转换 使用WEKA 作数据挖掘,面临的第一个问题往往是我们的数据不是ARFF 格式的
幸好,WEKA 还提供了对CSV 文件的支持,而这种格式是被很多其他软件,比如Excel,所支持的
现在我们打开“bank-data
利用WEKA 可以将CSV 文件格式转化成ARFF 文件格式
ARFF格式是WEKA 支持得最好的文件格式
此外,WEKA 还提供了通过JDBC 访问数据库的功能
“Explorer”界面 “Explorer”提供了很多功能,是WEKA 使用最多的模块
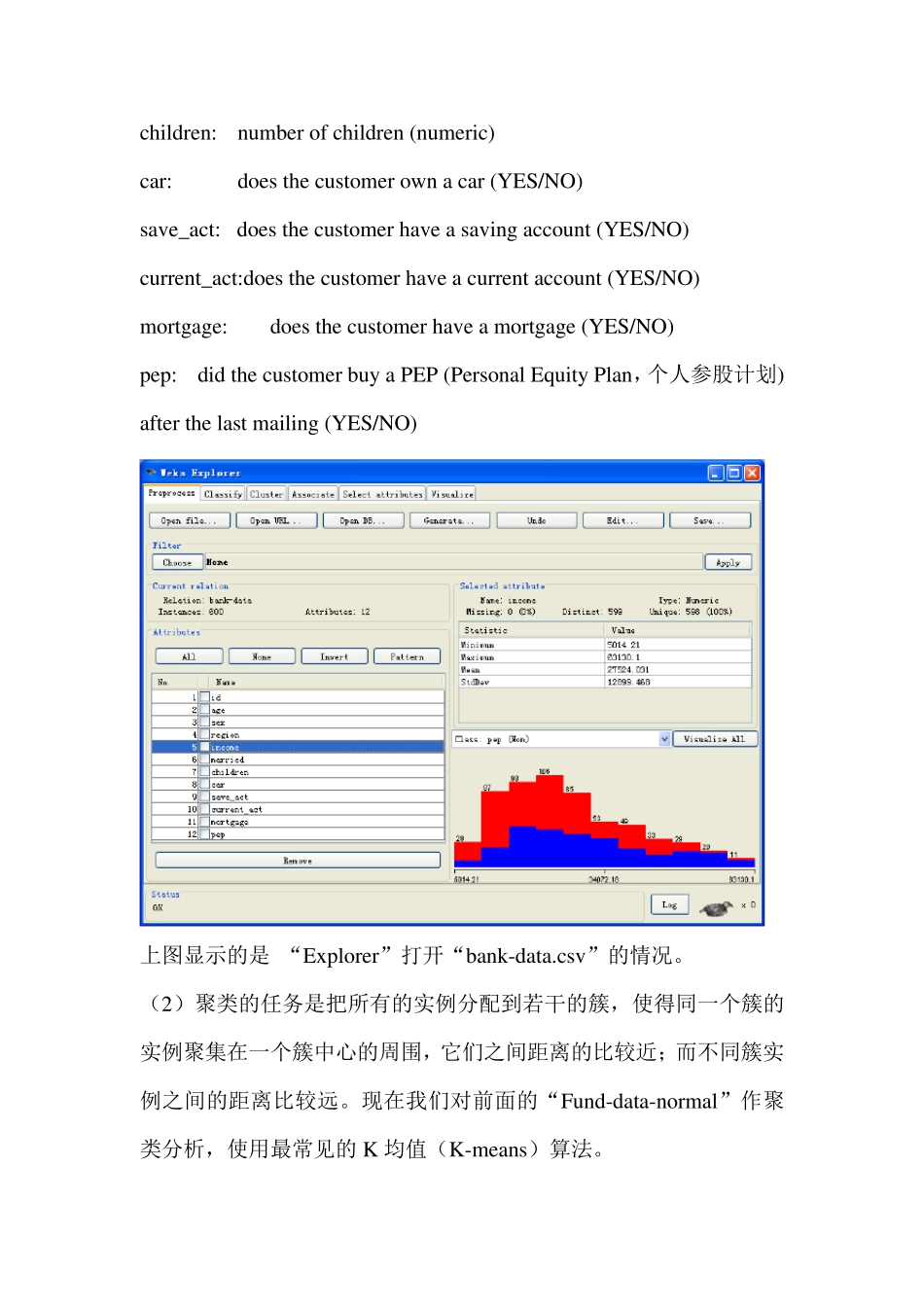
bank-data 数据各属性的含义如下: id: a unique identification number age: age of customer in years (numeric) sex: MALE / FEMALE region: inner_city/rural/suburban/town income: income of customer (numeric) married: is the customer married (YES/NO) children: number of children (numeric) car: does the customer own a car (YES/NO) save_act: does the customer have a saving account (YES/NO) current_act:does the customer have a current account (YES/NO) mortgage: does the c