Hbase 分析报告 本文基于环境 hadoop-0
4 和 hbase-0
3 编写 Hbase 是一个分布式开源数据库,基于 Hadoop 分布式文件系统,模仿并提供了基于 Google文件系统的 Bigtable 数据库的所有功能
Hbaes 的目标是处理非常庞大的表,可以用普通的计算机处理超过 10 亿行数据,并且有数百万列元素组成的数据表
Hbase 可以直接使用本地文件系统或者 Hadoop 作为数据存储方式,不过为了提高数据可靠性和系统的健壮性,发挥 Hbase 处理大数据量等功能,需要使用 Hadoop 作为文件系统,那么我们就先要了解 Hadoop 文件系统的基本特性和原理,才能更好地理解 Hbase 的工作方式
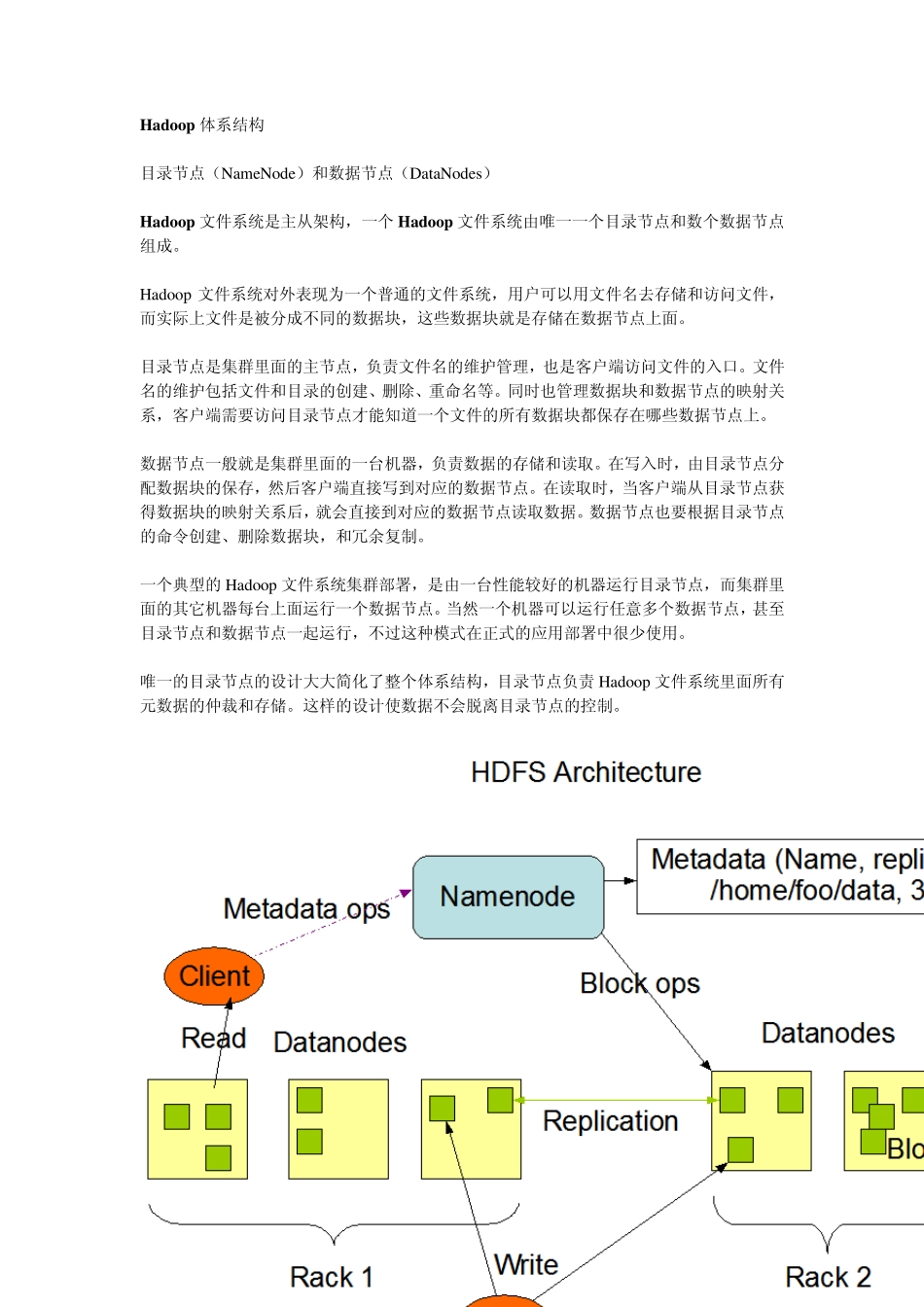
Hadoop 文件系统 Hadoop 文件系统是一个能够兼容普通硬件环境的分布式文件系统, 和现有的分布式文件系统不同的地方是 Hadoop 更注重容错性和兼容廉价的硬件设备,这样做是为了用很小的预算甚至直接利用现有机器就实现大流量和大数据量的读取
Hadoop 使用了 POSIX(可移植性操作系统接口)的设计来实现对文件系统文件流的读取
HDFS(Hadoop FileSy stem)原来是 Apache Nu tch 搜索引擎(从Lu cene 发展而来)开发的一个部分,后来独立出来作为一个 Apache 子项目
Hadoop 的假设与目标 1、 硬件出错,Hadoop 假设硬件出错是一种正常的情况,而不是异常,为的就是在硬件出错的情况下尽量保证数据完整性,HDFS 设计的目标是在成百上千台服务器中存储数据,并且可以快速检测出硬件错误和快速进行数据的自动恢复
2、 流数据读写,不同于普通的文件系统,Hadoop 是为了程序批量处理数据而设计的,而不是与用户的交互或者随机读写,所以 POSIX 对程序增加了许多硬性限制,程