使用分类树评估信用风险 ITELLIN 2005-11-29 这是SPSS 帮助菜单中个案研究的一个例子
假设银行有一个记载客户取得贷款交易信息的数据库,包括客户偿还或拖欠贷款的记录
使用分类树技术,银行方面可以分析及时还贷和有拖欠行为的客户特征,并能建立模型预测后续的贷款申请者拖欠银行贷款的可能性
信用数据文件名为 tree_credit
一、 建立模型 分类树过程提供几种不同的方法用来建立树模型
本案例使用的是预设的方法: CHAID——卡方自动交互检验
在计算的每一步中, CHAID 选择与因变量交互作用最强的自变量(预测因子)
如果某些自变量与因变量没有很强的显著性差别,这些自变量的分类将被合并
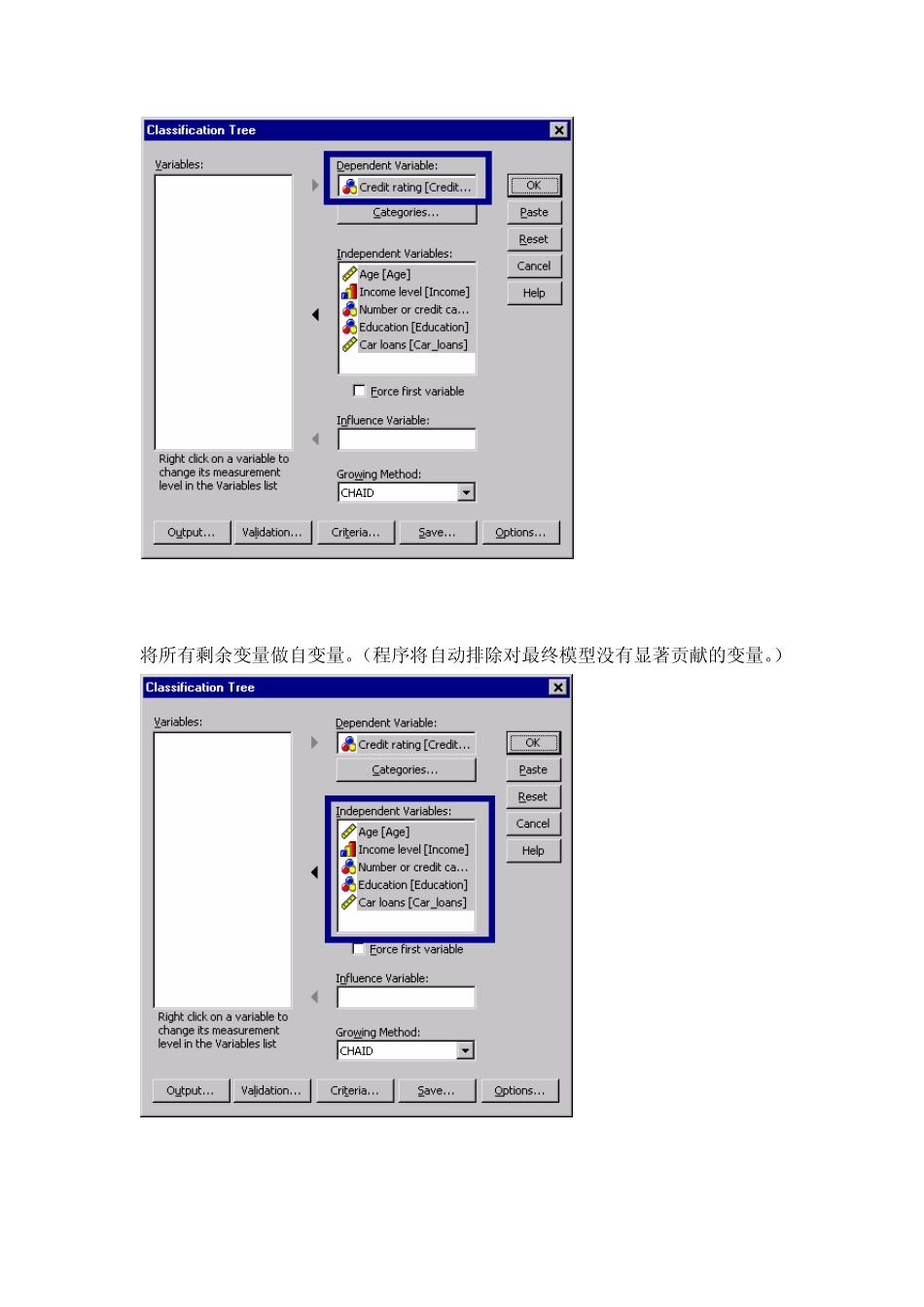
建立CHAID 树模型 从菜单中选择: 选择信用等级做因变量
将所有剩余变量做自变量
(程序将自动排除对最终模型没有显著贡献的变量
) 到这一步就可以运行程序产生基本的树模型,但是对最终模型我们打算选择一些附加输出并做一些小的调整
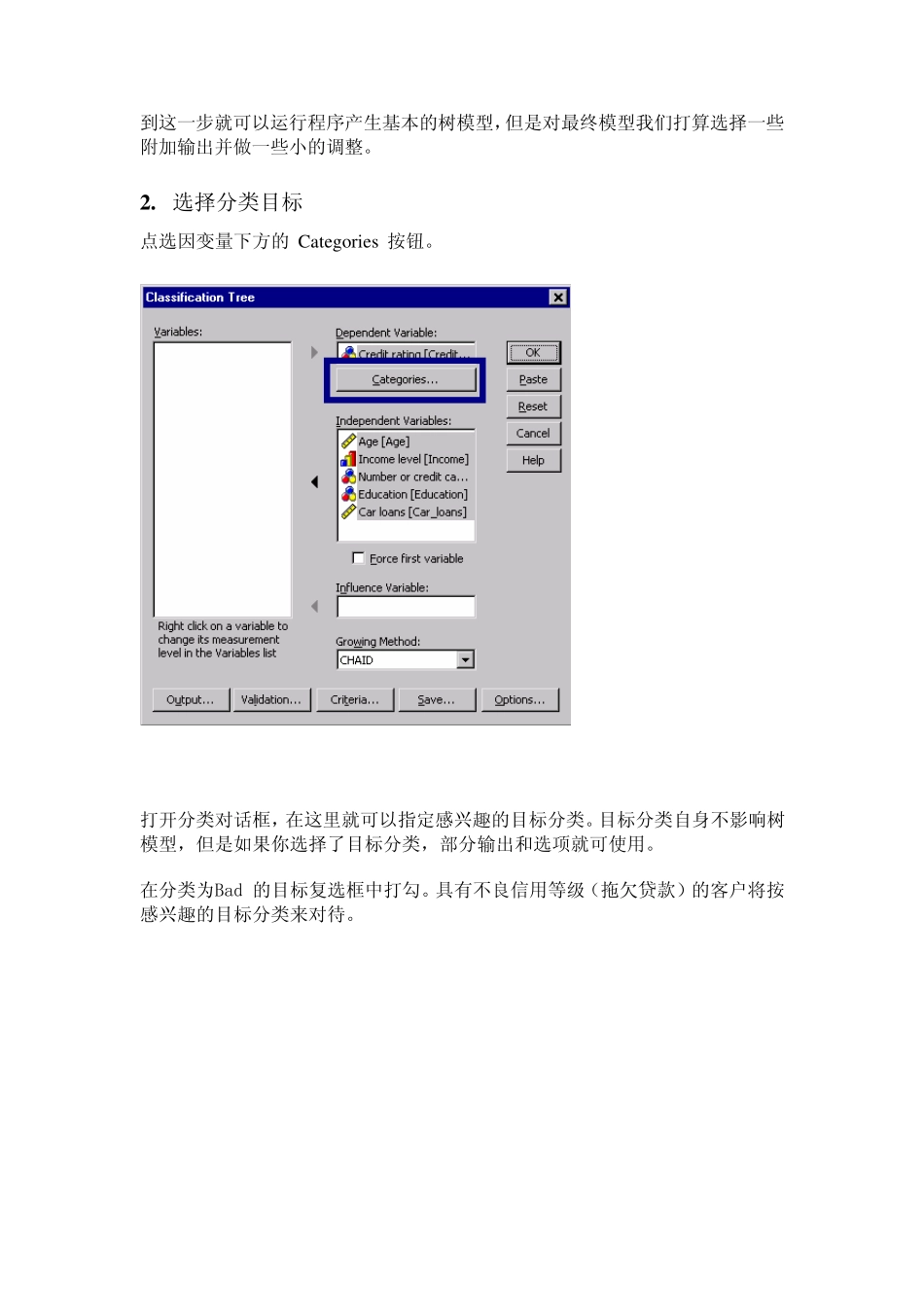
选择分类目标 点选因变量下方的 Categories 按钮
打开分类对话框,在这里就可以指定感兴趣的目标分类
目标分类自身不影响树模型,但是如果你选择了目标分类,部分输出和选项就可使用
在分类为Bad 的目标复选框中打勾
具有不良信用等级(拖欠贷款)的客户将按感兴趣的目标分类来对待
定义的生成标准 本例中,我们准备生成一个相当简单的树,所以要提高父结点和子节点的最小数量来限制树的生长
在分类树对话框中点击 Criteria
在 Minimum Number of Cases组中,父结点处键入 400,子结点处键入 200
选择附加输出 在分类树对话框中点击 Output
出现一个多页对话框,在这里可以选择各种附加输出类型
勾选Tree 页的Tree in ta