一、 问题描述 1
用户输入字母及其对应的权值,生成哈夫曼树; 2
通过最优编码的算法实现,生成字母对应的最优0、1 编码; 3
先序、中序、后序遍历哈夫曼树,并打印其权值
二、 方法思路 1
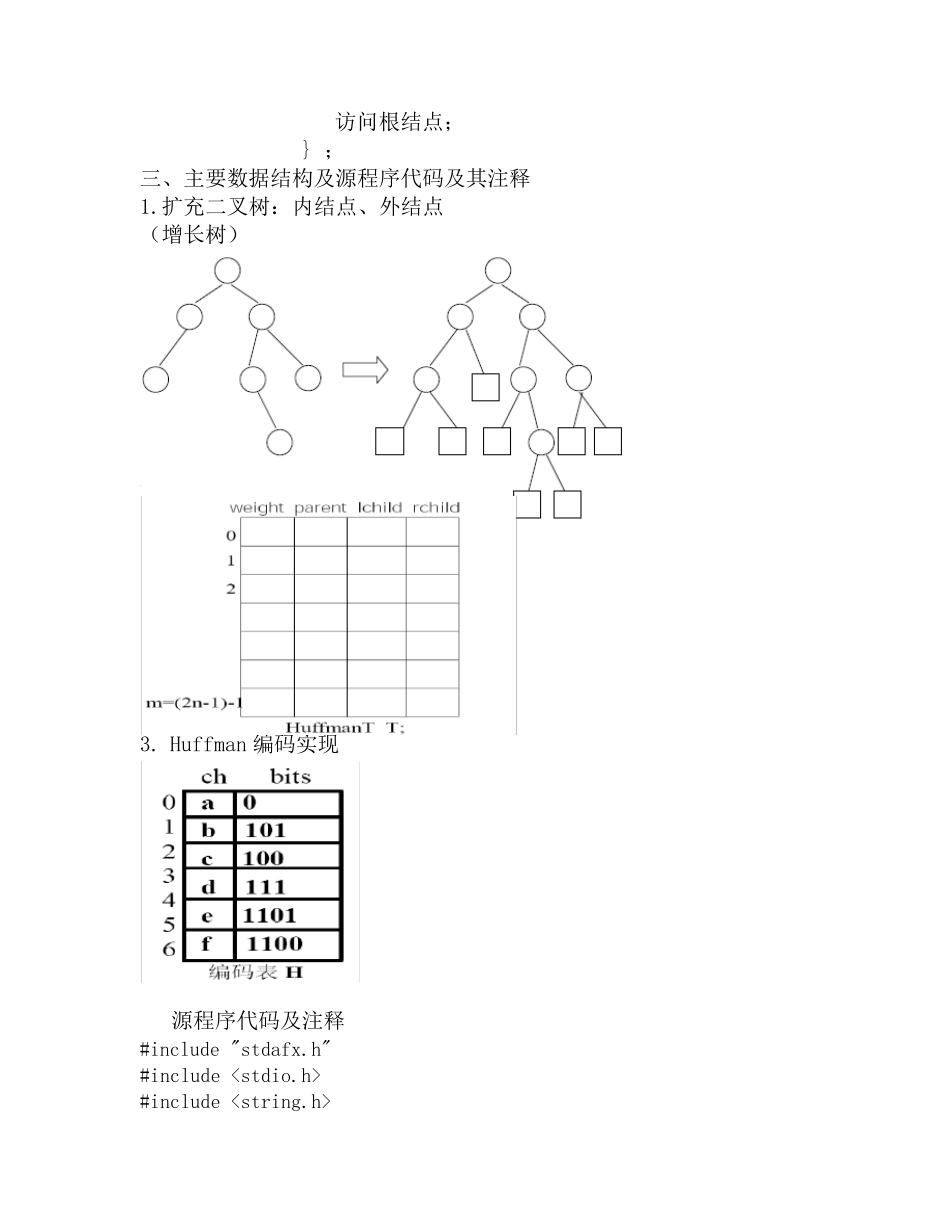
哈夫曼树算法的实现 §存储结构定义 #define n 100 /* 叶子树*/ #define m 2*(n) –1 /* 结点总数*/ typedef struct { /* 结点型*/ double weight ; /* 权值*/ int lchild ; /* 左孩子链*/ int rchild ; /* 右孩子链*/ int parent; /* 双亲链*/ 优点
}HTNODE ; typedef HTNODE HuffmanT[ m ] ; /* huffman 树的静态三叉链表表示*/ 算法要点 1)初始化:将 T[0],…T[m-1]共 2n-1 个结点的三个链域均置空( -1 ),权值为 0; 2)输入权值:读入n 个叶子的权值存于 T 的前 n 个单元 T[0],…T[n], 它们是 n 个独立的根结点上的权值; 3)合并:对森林中的二元树进行 n-1 次合并,所产生的新结点 依次存放在 T[i](n