大数据基本课程设计报告一、项目简介: 使用 hadoop 中的 hive、mapreduce 以及 HBASE 对网上的一种搜狗五百万的数进行了一种比较实际的数据分析
搜狗五百万数据,是通过解决后的搜狗搜索引擎生产数据,具有真实性,大数据性,可以较好的满足分布式计算应用开发课程设计的数据规定
搜狗数据的数据格式为:访问时间\t 顾客 ID\t[查询词]\t 该 URL 在返回成果中的排名\t 顾客点击的顺序号\t 顾客点击的 URL
其中,顾客 ID 是根据顾客使用浏览器访问搜索引擎时的 Cookie 信息自动赋值,即同一次使用浏览器输入的不同查询相应同一种顾客 ID
二、操作规定1
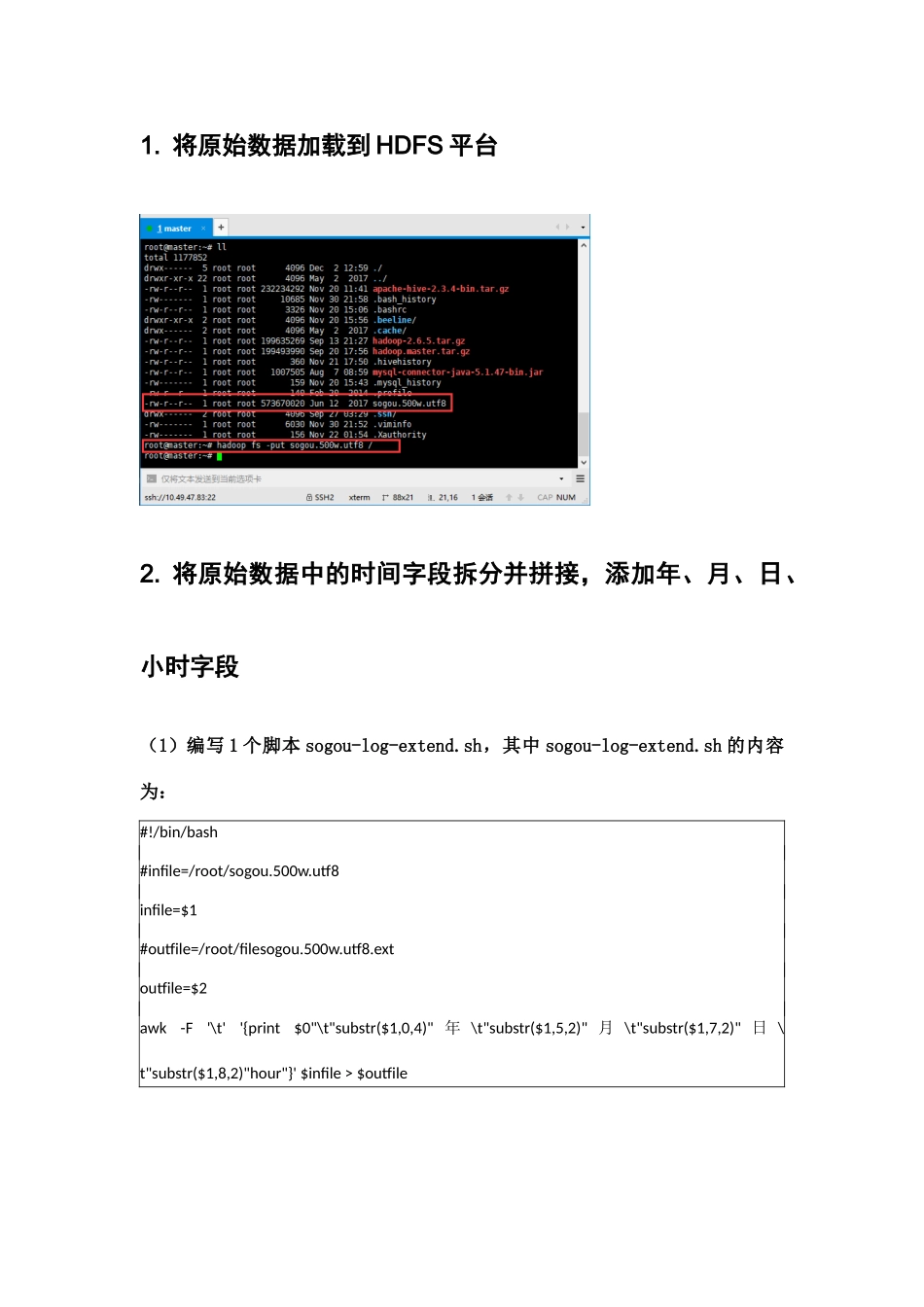
将原始数据加载到 HDFS 平台
将原始数据中的时间字段拆分并拼接,添加年、月、日、小时字段
将解决后的数据加载到 HDFS 平台
如下操作分别通过 MR 和 Hive 实现
查询总条数非空查询条数无反复总条数独立 UID 总数查询频度排名(频度最高的前 50 词)查询次数不小于 2 次的顾客总数查询次数不小于 2 次的顾客占比Rank 在 10 以内的点击次数占比直接输入 URL 查询的比例查询搜索过”仙剑奇侠传“的 uid,并且次数不小于 35
将 4 每环节生成的成果保存到 HDFS 中
将 5 生成的文献通过 Java API 方式导入到 HBase(一张表)
通过 HBase shell 命令查询 6 导出的成果
三、实验流程1
将原始数据加载到 HDFS 平台2
将原始数据中的时间字段拆分并拼接,添加年、月、日、小时字段(1)编写 1 个脚本 sogou-log-extend
sh,其中 sogou-log-extend
sh 的内容为:#
/bin/bash#infile=/root/sogou
utf8infil