第五章索引压缩2014-4-2章节框架•词项统计特性1
Heaps定律2
Zipf定律•词典压缩1
长字符串和词项指针2
前端编码•倒排记录表压缩1
可变字节编码2
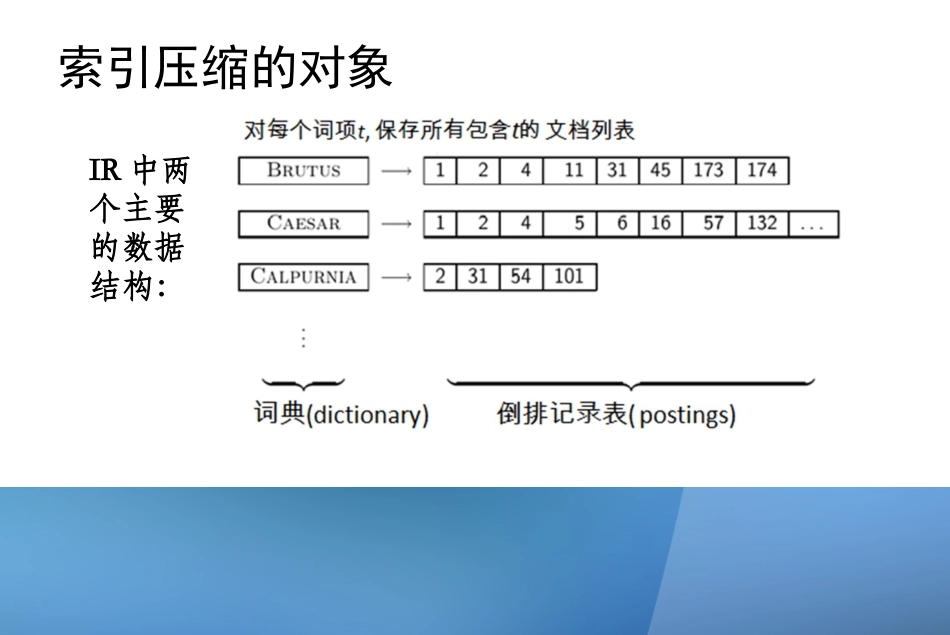
γ编码索引压缩的对象IR中两个主要的数据结构:索引压缩的意义1
节省磁盘空间——目标:达到1:4的压缩比例2
增加高速缓存技术的利用率——目标:把常用的条目放入内存存储,减少系统应答时间3
加快数据从磁盘到内存的传输速度——目标:结合高效的解压缩算法提高系统运行速度•本章介绍的解压算法都很高效,可以达到以上目标•索引压缩通常是无损压缩,有损压缩技术在预处理阶段介绍(2
2)本章所用语料库存储所有的(词项ID,文档ID)对需要1
28GB初步处理后的文档集大小为960MB未压缩的文档集词典存储空间为11
2MB未压缩的倒排记录表大小为250MB初步处理后的语料库Heaps定律——词项数目的估计词项数目的估计:Heaps定律M=kTbM是词汇表大小,T是文档集的大小(文档集合中所有词条的个数,即所有文档大小之和)参数k和b的一个经典取值是:30≤k≤100及b≈0
Heaps定律通过文档集合中的词条数来估计词汇表大小,词汇表大小会随着文档集的大小增长而增长
Heaps定律结论:随着文档数目的增加,词汇量会持续增长而不会稳定到一个最大值
大规模文档集的词汇量也会非常大
Zipf定律——对词项的分布建模在自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比
词项分布的估计:Zipf定律cfi∝(1/i)如果出现最多的词项的出现次数是cf1的话,出现第二多的词项的出现次数就是cf1的一半,出现第三多的词项出现次数会是cf1的1/3,其余均可依此类推
注:cfi是文档频率(collectionfrequency):词项ti在所有文档中出现的次数(不是出现该词项的文档数目df)词典压缩•词典压缩的