第1页, 共12页 MapReduce工作原理 1 MapReduce 原理(一) 1
1 MapReduce 编程模型 MapRedu ce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果
简单地说,MapRedu ce就是"任务的分解与结果的汇总"
在Hadoop中,用于执行MapRedu ce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的
一个Hadoop集群中只有一台JobTracker
在分布式计算中,MapRedu ce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和redu ce,map负责把任务分解成多个任务,redu ce负责把分解后多任务处理的结果汇总起来
需要注意的是,用MapRedu ce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理
2 MapReduce 处理过程 在Hadoop中,每个MapRedu ce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和redu ce阶段
这两个阶段分别用两个函数表示,即map函数和redu ce函数
map函数接收一个形式的输入,然后同样产生一个形式的中间输出,Hadoop函数接收一个如形式的输入,然后对这个v alu e集合进行处理,每个redu ce产生0或1个输出,redu ce的输出也是形式的
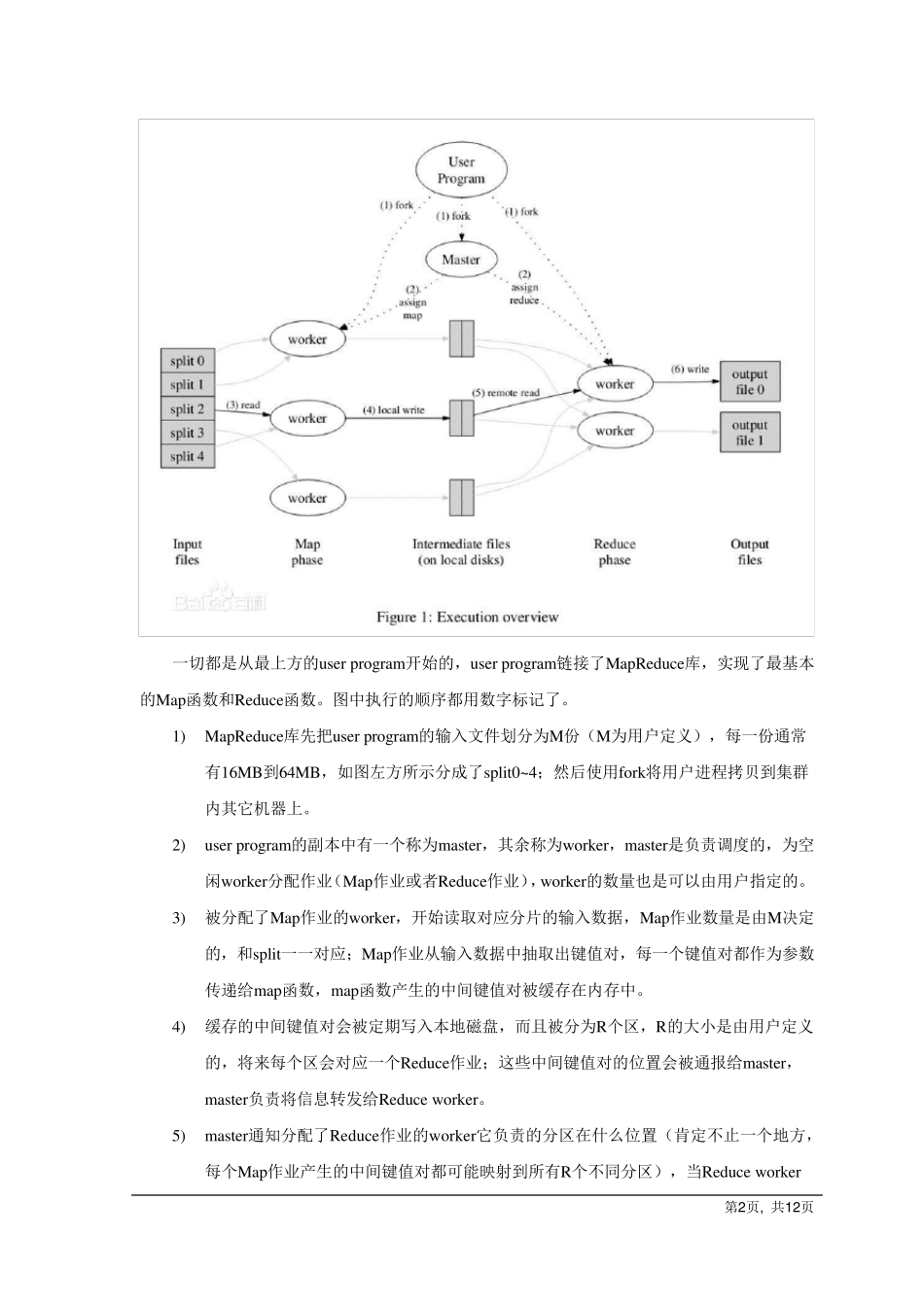
第2 页, 共1 2 页 一切都是从最上方的user program开始的,user program链接了MapR