标准文案 大全 第1章 数据仓库建设 1
1 数据仓库总体架构 专家系统接收增购项目车辆TCMS 或其他子系统通过车地通信传输的实时或离线数据,经过一系列综合诊断分析,以各种报表图形或信息推送的形式向用户展示分析结果
针对诊断出的车辆故障将给出专家建议处理措施,为车辆的故障根因修复提供必要的支持
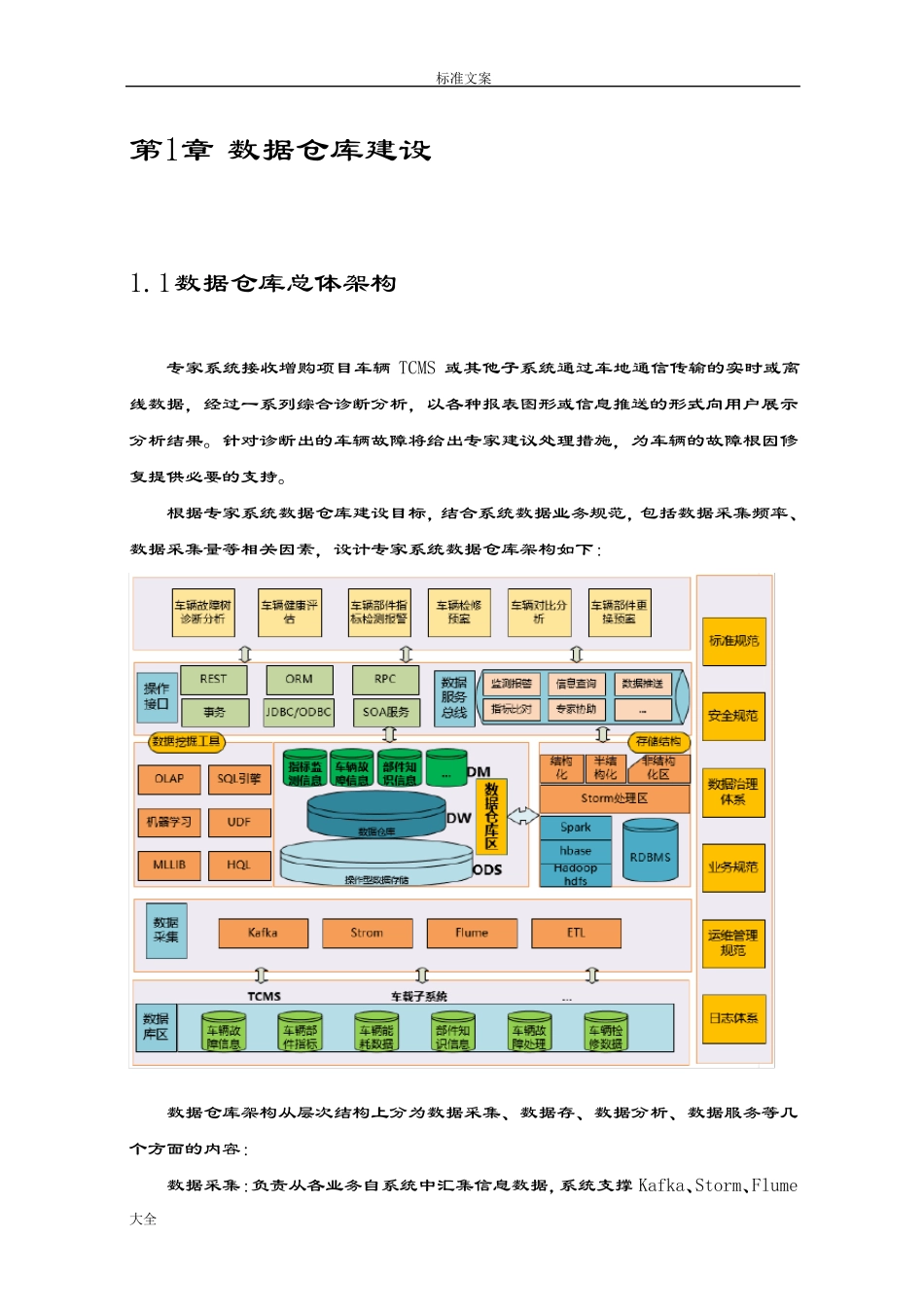
根据专家系统数据仓库建设目标,结合系统数据业务规范,包括数据采集频率、数据采集量等相关因素,设计专家系统数据仓库架构如下: 数据仓库架构从层次结构上分为数据采集、数据存、数据分析、数据服务等几个方面的内容: 数据采集:负责从各业务自系统中汇集信息数据,系统支撑 Kafka、Storm、Flume标准文案 大全 及传统的ETL 采集工具
数据存储:本系统提供Hdfs、Hbase 及RDBMS 相结合的存储模式,支持海量数据的分布式存储
数据分析:数据仓库体系支持传统的OLAP 分析及基于 Spark 常规机器学习算法
数据服务总线:数据系统提供数据服务总线服务,实现对数据资源的统一管理和调度,并对外提供数据服务
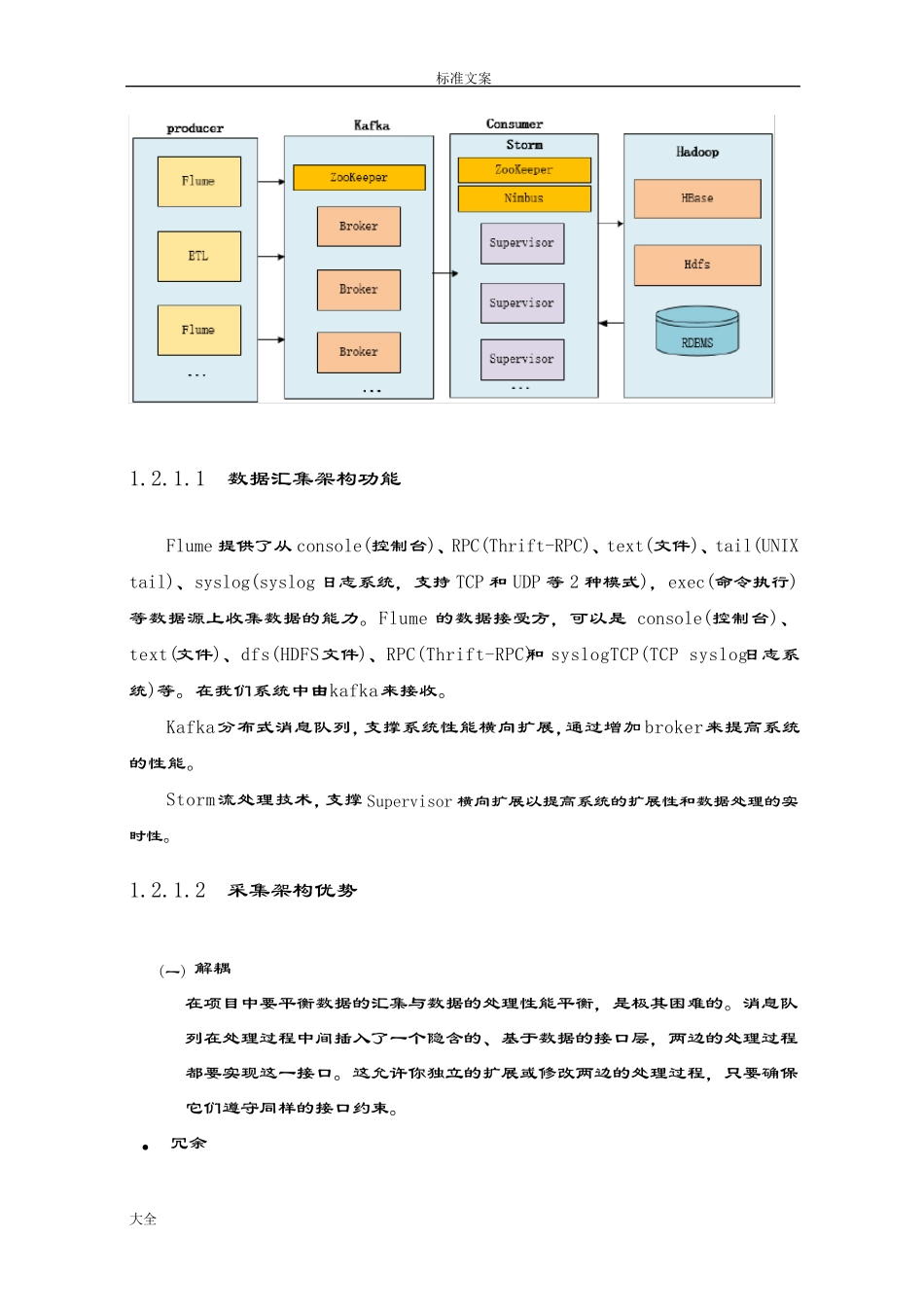
2 数据采集 专家系统数据仓库数据采集包括两个部分内容:外部数据汇集、内部各层数据的提取与加载
外部数据汇集是指从 TCMS、车载子系统等外部信息系统汇集数据到专家数据仓库的操作型存储层(ODS);内部各层数据的提取与加载是指数据仓库各存储层间的数据提取、转换与加载
1 外部数据汇集 专家数据仓库数据源包括列车监控与检测系统(TCMS)、车载子系统等相关子系统,数据采集的内容分为实时数据采集和定时数据采集两大类,实时数据采集主要对于各项检测指标数据;非实时采集包括日检修数据等
根据项目信息汇集要求,列车指标信息采集具有采集数据量大,采集频率高的特点,考虑到系统后期的扩展,因此在数据数据采集方面,要求采集体系支持高吞吐量、高频率、海量数据采集,同时系统