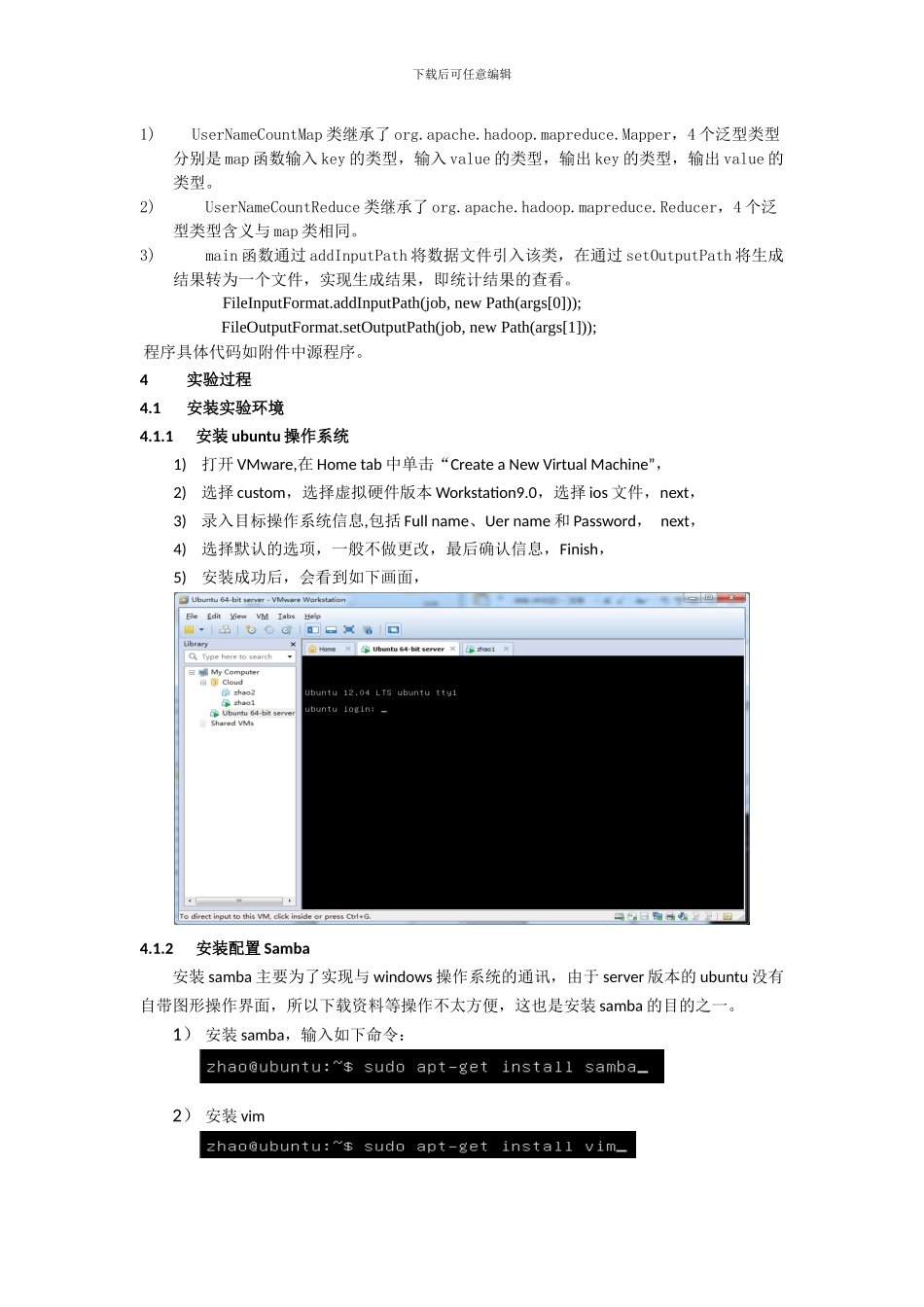
下载后可任意编辑Hadoop 云计算实验报告下载后可任意编辑Hadoop 云计算实验报告1实验目的在虚拟机 Ubuntu 上安装 Hadoop 单机模式和集群;编写一个用 Hadoop 处理数据的程序,在单机和集群上运行程序
2实验环境虚拟机:VMware 9操作系统:ubuntu-12
04-server-x64(服务器版),ubuntu-14
10-desktop-amd64(桌面版)Hadoop 版本:hadoop 1
1Jdk 版本:jdk-7u80-linux-x64Eclipse 版本:eclipse-jee-luna-SR2-linux-gtk-x86_64Hadoop 集群:一台 namenode 主机 master,一台 datanode 主机 salve,master 主机 IP 为 10
223,slave 主机 IP 为 10
3实验设计说明3
1主要设计思路 在 ubuntu 操作系统下,安装必要软件和环境搭建,使用 eclipse 编写程序代码
实现大数据的统计
本次实验是统计软件代理系统操作人员处理的信息量,即每个操作人员出现的次数
程序设计完成后,在集成环境下运行该程序并查看结果
2算法设计 该算法首先将输入文件都包含进来,然后交由 map 程序处理,map 程序将输入读入后切出其中的用户名,并标记它的数目为 1,形成的形式,然后交由 reduce 处理,reduce 将相同 key 值(也就是 word)的 value 值收集起来,形成的形式,之后再将这些 1 值加起来,即为用户名出现的个数,最后将这个对以TextOutputFormat 的形式输出到 HDFS 中
3程序说明下载后可任意编辑1) UserNameCountMap 类继承了 org
apache
hadoop
mapreduce