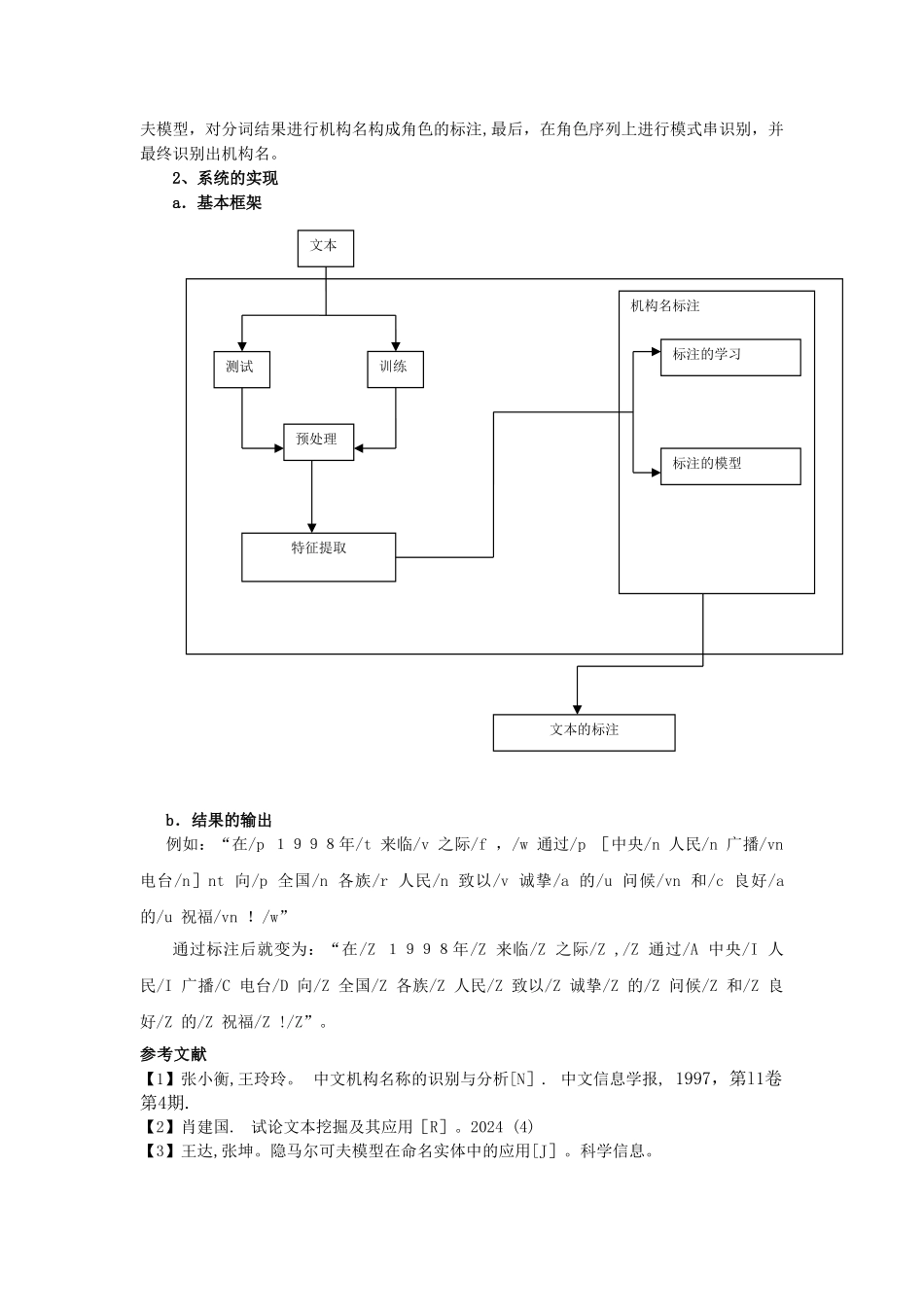
中文机构名识别的设计与实现课题背景 随着互联网的大规模普及和社会信息化程度的提高, 文本信息的快速积累使公司、政府和科研机构在信息处理和使用中面临前所未有的挑战
一方面, 互联网和各种信息机构每天都不断产生大量的有价值的文本数据; 而另一方面, 因为技术手段的落后, 从这些文本数据资源中猎取需要的信息十分困难
人们迫切需要讨论出方便有效的工具去从大规模文本信息资源中提取符合需要的简洁、精炼、可理解的知识, 文本挖掘就是为解决这个问题而产生的讨论方向
文本挖掘也称为文本数据挖掘或文本知识发现, 它是指从大量文本数据中抽取事先未知的、可理解的、最终可用的知识的过程, 同时运用这些知识更好地组织信息以便将来参考
【2】 文本挖掘的主要目的是从非结构化的文本文档中提取有趣的、重要的模式和知识
所以它可以看成是基于数据库的数据挖掘或知识发现的扩展
但与传统的数据挖掘相比, 文本挖掘有其独特之处, 主要表现在: 文档本身是半结构化或非结构化的, 无确定形式并且缺乏机器可理解的语义; 而数据挖掘的对象以数据库中的结构化数据为主, 并利用关系表等存储结构来发现知识
直观地说, 当数据挖掘的对象完全由文本这种数据类型组成时, 这个过程就称为文本挖掘
文本挖掘在许多方面具有广泛的应用,例如:主动信息服务方面、信息检索系统方面、专利信息分析方面等等
选题意义 文本挖掘最基础、最重要的步骤就是命名实体的识别,识别出文本中的人名、机构名称等
命名实体识别(NE)是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等
其中机构名称泛指机关、团体或其他企事业单位,包括学校、公司、医院、讨论所和政府机关等的名称
机构名称是专有名词的一个子集,数目也特别庞大
与人名地名相比,机构名称这类专有名词还很不稳定.随着社会的进展,新机构不断涌现,旧机构不断被淘汰、改组或更名
此外,机构名称的组