实验3MapReduce编程初级实践实验3MapReduce编程初级实践1
通过实验掌握基本的MapReduce编程方法;2
掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等
实验平台已经配置完成的Hadoop伪分布式环境
实验内容和要求1
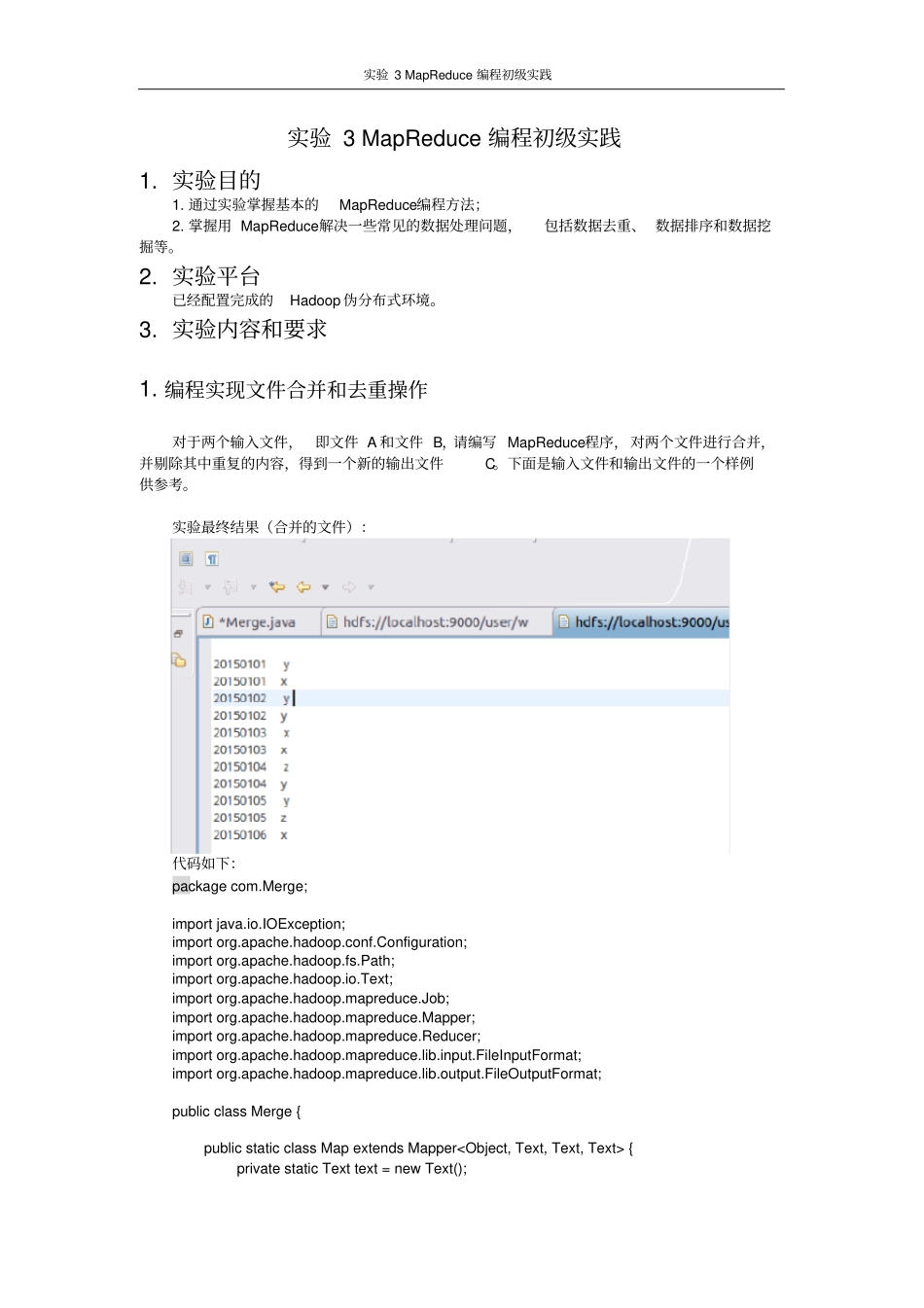
编程实现文件合并和去重操作对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C
下面是输入文件和输出文件的一个样例供参考
实验最终结果(合并的文件):代码如下:packagecom
Merge;importjava
IOException;importorg
apache
hadoop
Configuration;importorg
apache
hadoop
Path;importorg
apache
hadoop
Text;importorg
apache
hadoop
mapreduce
Job;importorg
apache
hadoop
mapreduce
Mapper;importorg
apache
hadoop
mapreduce
Reducer;importorg
apache
hadoop
mapreduce
FileInputFormat;importorg
apache
hadoop
mapreduce
output
FileOutputFormat;publicclassMerge{publicstaticclassMapextendsMapper{privatestaticTexttext=newText();实验3MapReduce编程初级实践publicvoidmap(Objectkey,Textvalue,Con