应用SPSS 软件进行列联表分析 在许多调查研究中,所得到的数据大多为定性数据,即名义或定序尺度测量的数据
例如在一项全球教育水平的研究中,调查了400 余人的个人信息,包括性别、学历、种族等,对原始资料进行整理就可以得到频数分布表
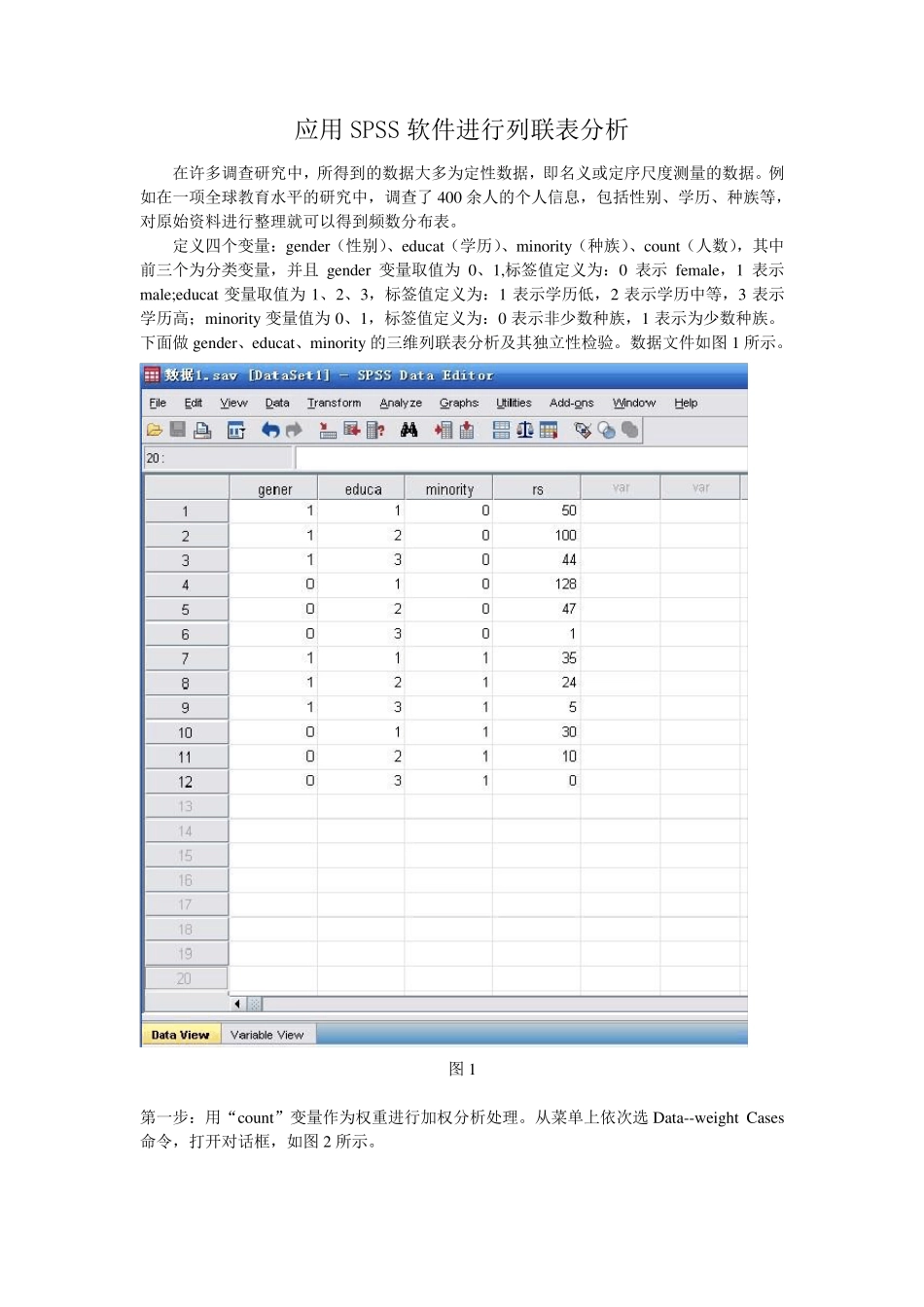
定义四个变量:gender(性别)、educat(学历)、minority(种族)、count(人数),其中前三个为分类变量,并且gender 变量取值为0、1,标签值定义为:0 表示female,1 表示male;educat 变量取值为1、2、3,标签值定义为:1 表示学历低,2 表示学历中等,3 表示学历高;minority变量值为0、1,标签值定义为:0 表示非少数种族,1 表示为少数种族
下面做gender、educat、minority的三维列联表分析及其独立性检验
数据文件如图1 所示
图1 第一步:用“count”变量作为权重进行加权分析处理
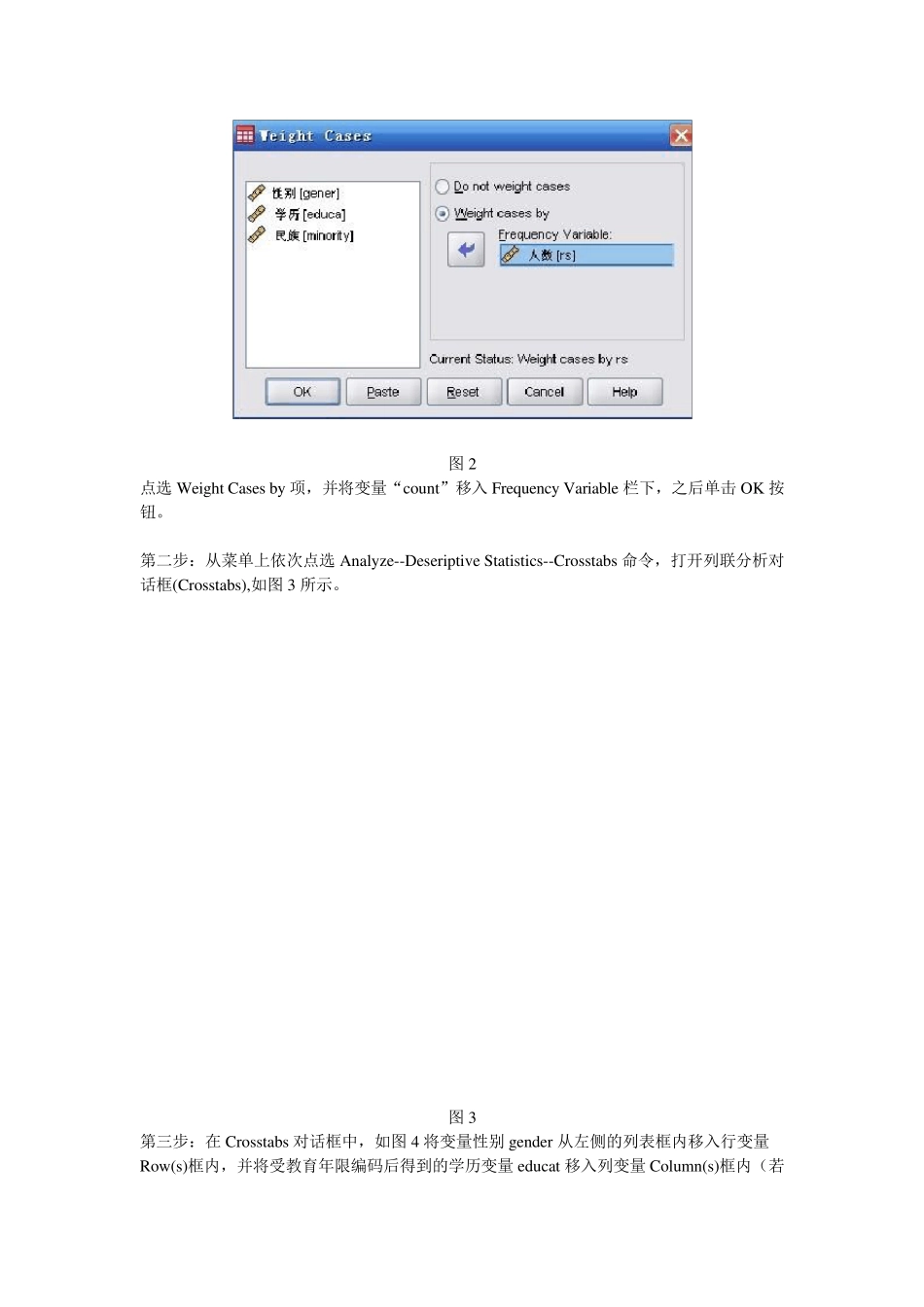
从菜单上依次选 Data--weight Cases命令,打开对话框,如图2 所示
图2 点选Weight Cases by 项,并将变量“count”移入 Frequency Variable 栏下,之后单击 OK 按钮
第二步:从菜单上依次点选Analyze--Deseriptive Statistics--Crosstabs 命令,打开列联分析对话框(Crosstabs),如图3 所示
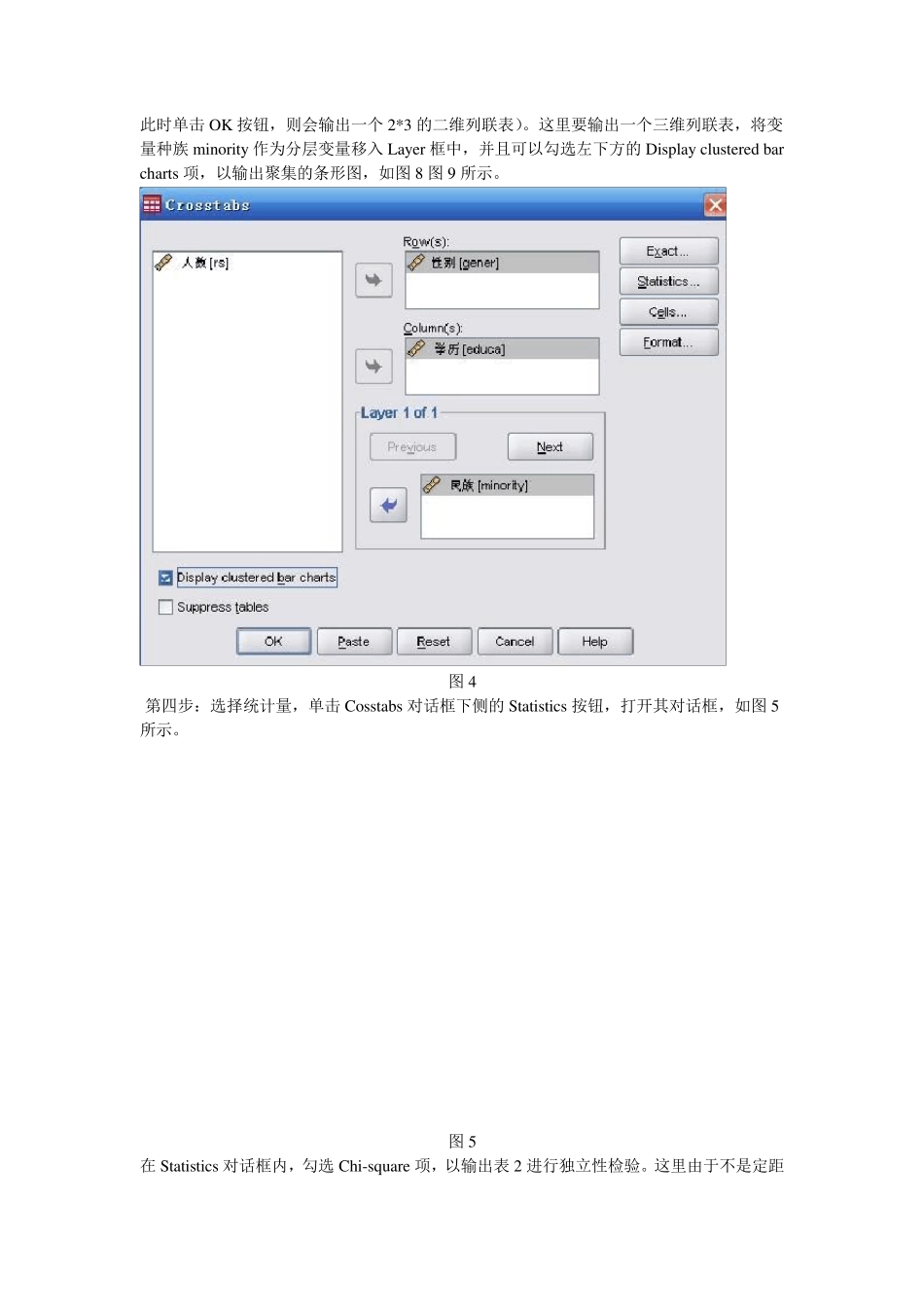
图3 第三步:在 Crosstabs 对话框中,如图4 将变量性别 gender 从左侧的列表框内移入行变量Row(s)框内,并将受教育年限编码后得到的学历变量educat 移入列变量Column(s)框内(若此时单击OK 按钮,则会输出一个2*3 的二维列联表)
这里要输出一个三维列联表,将变量种族 minority 作为分层变量移入 Lay er 框中,并且可以勾选左下方的Display