基本概念与解决方法经典的频繁项目集生成算法分析Apriori算法的性能瓶颈问题Apriori的改进算法对项目集格空间理论的发展关联规则挖掘中的一些更深入的问题第三章关联规则挖掘理论和算法第三章关联规则挖掘理论和算法第三章关联规则挖掘理论和算法第三章关联规则挖掘理论和算法关联规则挖掘是数据挖掘研究的基础关联规则挖掘是数据挖掘研究的基础关联规则挖掘(AssociationRuleMining)是数据挖掘中研究较早而且至今仍活跃的研究方法之一
最早是由Agrawal等人提出的(1993)
最初提出的动机是针对购物篮分析(BasketAnalysis)问题提出的,其目的是为了发现交易数据库(TransactionDatabase)中不同商品之间的联系规则
关联规则的挖掘工作成果颇丰
例如,关联规则的挖掘理论、算法设计、算法的性能以及应用推广、并行关联规则挖掘(ParallelAssociationRuleMining)以及数量关联规则挖掘(QuantitiveAssociationRuleMining)等
关联规则挖掘是数据挖掘的其他研究分支的基础
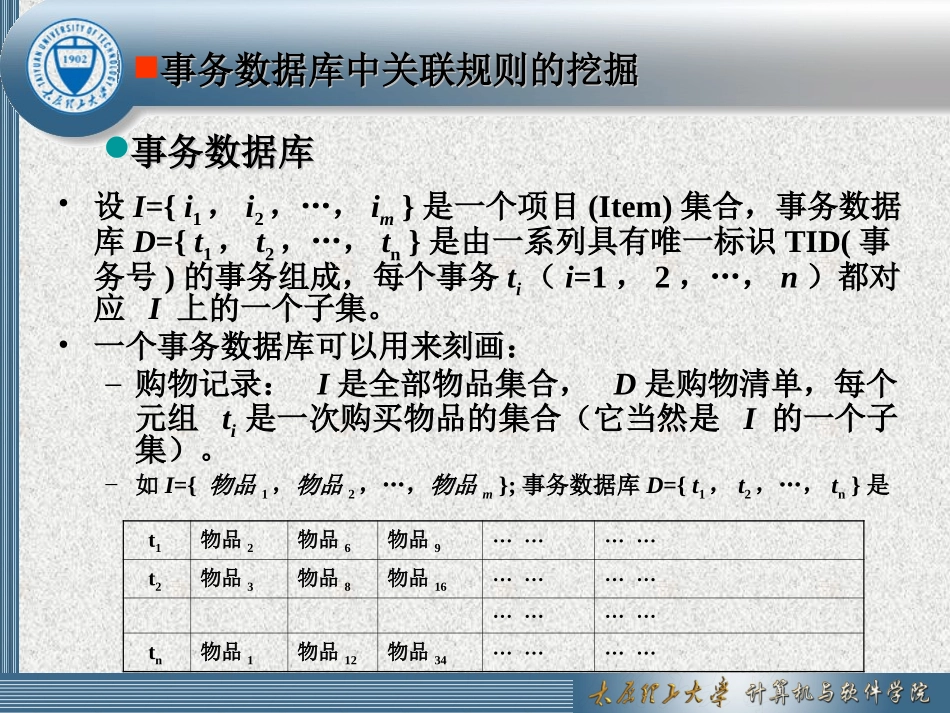
基本概念与解决方法基本概念与解决方法基本概念与解决方法基本概念与解决方法事务数据库事务数据库•设I={i1,i2,…,im}是一个项目(Item)集合,事务数据库D={t1,t2,…,tn}是由一系列具有唯一标识TID(事务号)的事务组成,每个事务ti(i=1,2,…,n)都对应I上的一个子集
•一个事务数据库可以用来刻画:–购物记录:I是全部物品集合,D是购物清单,每个元组ti是一次购买物品的集合(它当然是I的一个子集)
–如I={物品1,物品2,…,物品m};事务数据库D={t1,t2,…,tn}是事务数据库中关联规则的挖掘事务数据库中关联规则的挖掘t1物品2物品6物品9…………t2物品3物品8物品16……………………