样本组织的 3 种方法随机分组法: 样本量大的用随机分组法, 把 2/3 样本作为学习样本构建模型,剩余 1/3 作为测试样本,测试模型性能
K折交叉验证法: 样本量不多,交叉分组分为K 组,依次从 K 组数据中选 1组作为测试样本,其余9 组作为学习样本
留一法: 样本量很少,留 1 例作为测试样本,其余作为学习样本,依次循环
关于数据的预处理二值型数据(是否归一化变成0 或 1)分类型和排序型就是变成0
4(如胃癌分期等)数值型就是血压 , 心率之类的具体数据对数值型数据进行归一化, 就是要让数值都变化在【0,1 】比较大的数值:常用的几种十进计数法,用于比较大的数值,分散又比较开,可以直接把这些数值除以10 的整次幂(就是 10 的平方,三次方之类)对于数据不多且数值不大:可以采用最小- 最大归一法:把取值范围定在 [0,1] ,就可简化公式为:新值 =(原值 - 原 min)/ (原 max-原 min)这样处理以后数据中最大值变为1 最小值变为 0 Z 分数归一法:新值 =(原值 - 均值) / 标准差此法主要用于原始数据取值范围无法知道或原始数据中的最大值或最小值与均值偏离很大最后一种对数归一法:直接计算器In 原值就出来新值了,对数归一法对原始数据压缩后不引起信息的损失3
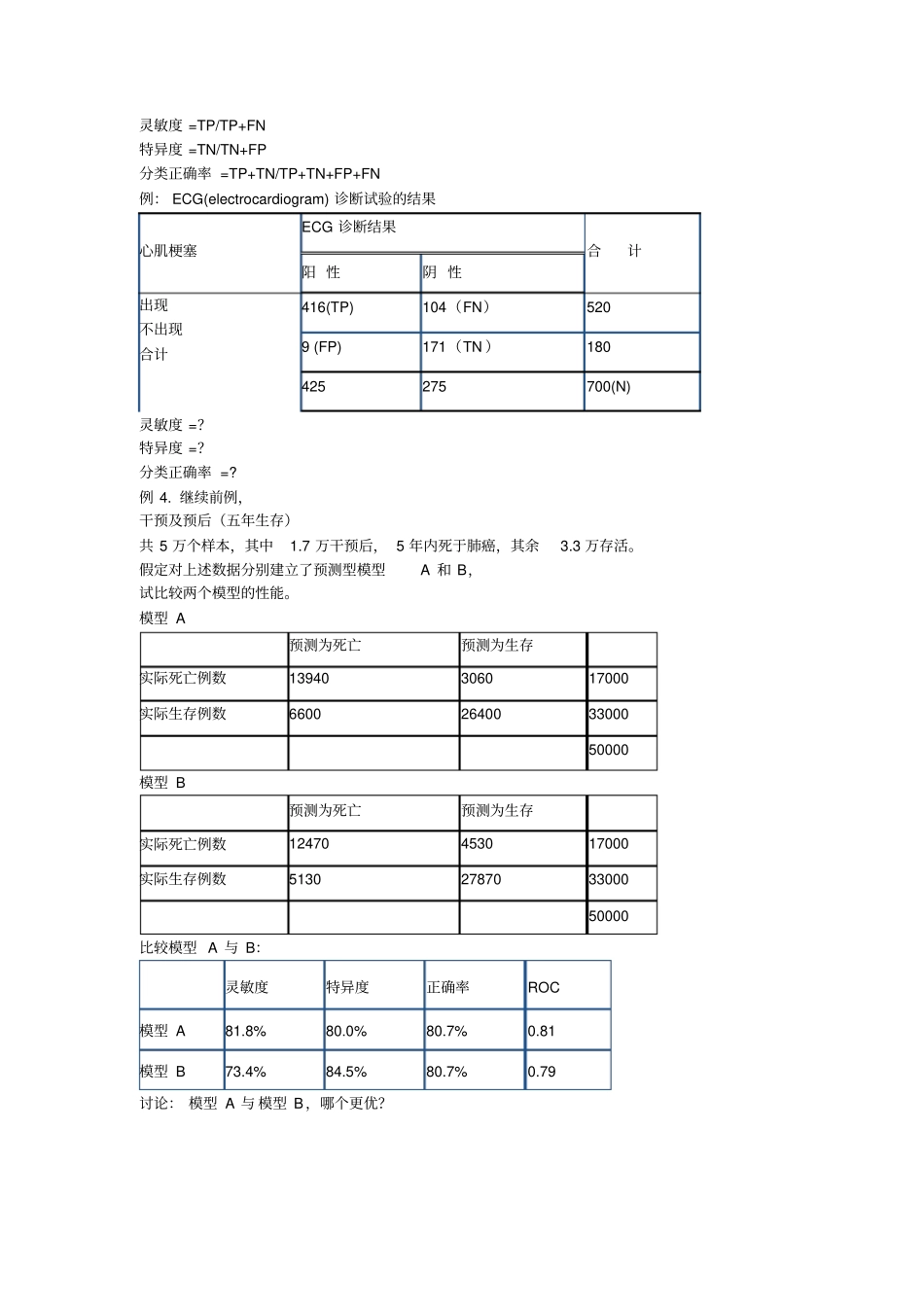
比较性能四格六格表:灵敏度、特异度、正确率和ROC曲线
要把提供的 6 格表合并为 4 格表4
回归分类决策树模型表达规则三种模型比较性能:分别是logistic回归决策树人工神经网络5
聚类关联: 如何取舍样本组织例 1
预测型模型肺癌 干预 (手术 /手术+化疗 )及预后(五年生存)共 5 万个样本,其中1
7 万干预后 5 年内死于肺癌如何组织数据进行数据挖掘
共 1000 个,其中 315 个五年内死亡如何组织数据
共 49 个, 1