2 0 0 9 级数据结构实验报告 实验名称: 使用链表实现各种排序算法 学生姓名: 桂柯易 班 级: 2 0 0 9 2 1 1 1 2 0 班内序号: 0 7 学 号: 0 9 2 1 0 5 8 0 日 期: 2 0 1 0 年1 2 月1 9 日 1
实验要求 【实验目的】 通过选择实验内容中的两个题目之一,学习、实现、对比各种排序算法,掌握各种排序算法的优劣,以及各种算法的使用的情况
【实验内容】 使用链表实现下面各种排序算法,并进行比较
排序算法如下: ① 插入排序; ② 冒泡排序; ③ 快速排序; ④ 简单选择排序; ⑤ 其他
具体要求如下
① 测试数据分成三类:正序、逆序、随机数据
② 对于这三类数据,比较上述排序算法中关键字的比较次数和移动次数(其中关键字交换计为 3次移动)
③ 对于这三类数据,比较上述排序算法中不同算法的执行时间,精确到微秒(选作)
④ 对②和③的结果进行分析,验证上述各种算法的时间复杂度
⑤ 编写 main()函数测试各种排序算法的正确性
程序分析 2
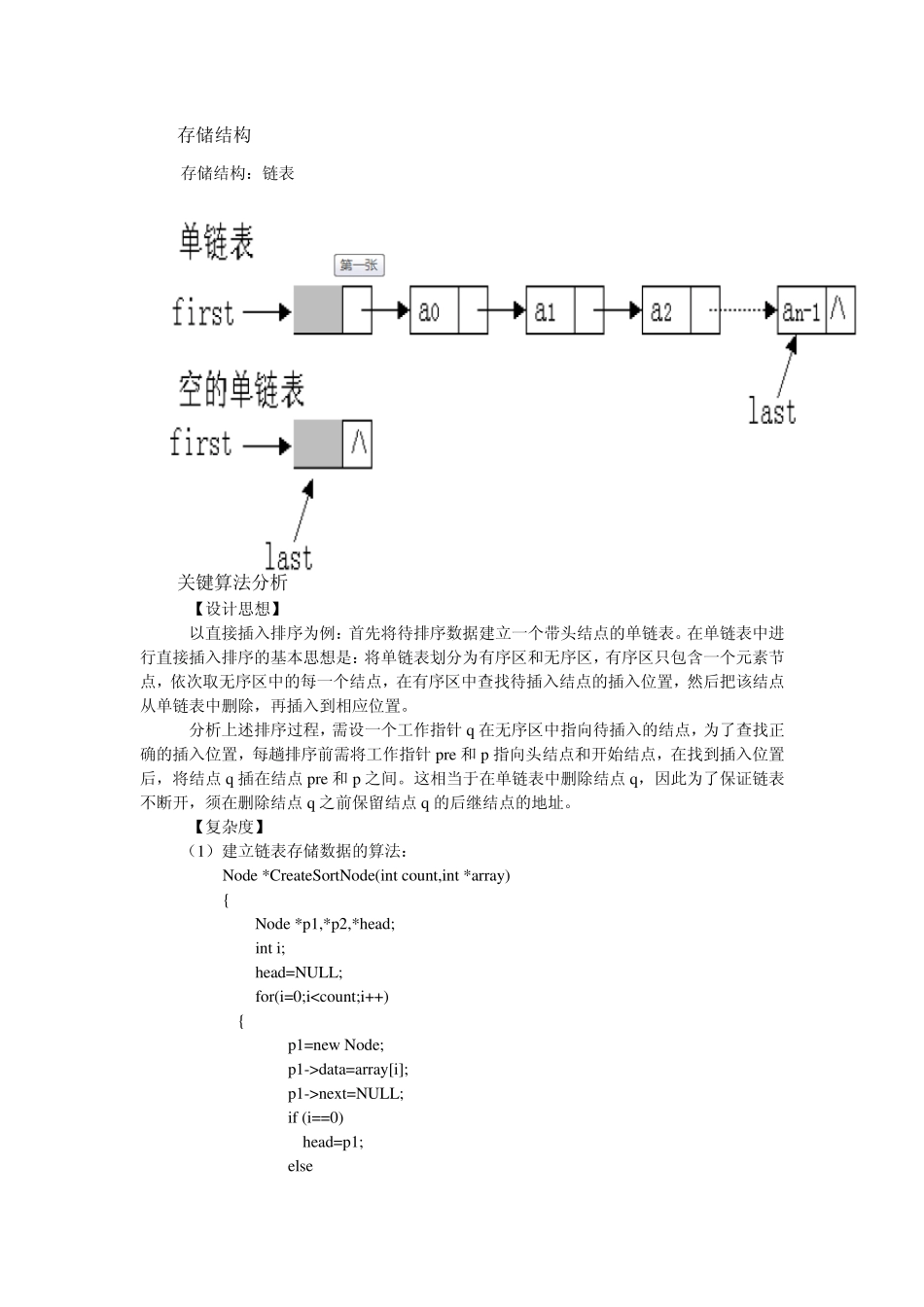
1 存储结构 存储结构:链表 2
2 关键算法分析 【设计思想】 以直接插入排序为例:首先将待排序数据建立一个带头结点的单链表
在单链表中进行直接插入排序的基本思想是:将单链表划分为有序区和无序区,有序区只包含一个元素节点,依次取无序区中的每一个结点,在有序区中查找待插入结点的插入位置,然后把该结点从单链表中删除,再插入到相应位置
分析上述排序过程,需设一个工作指针 q 在无序区中指向待插入的结点,为了查找正确的插入位置,每趟排序前需将工作指针 pre 和 p 指向头结点和开始结点,在找到插入位置后,将结点q 插在结点pre 和 p 之间
这相当于在单链表中删除结点q,因此为了保证链表不断开,须在删除结点q 之前保留结点q 的后继结点的地址
【复杂度】 (1)