- 1 - Panel Data 模型的EView s 操作过程 两种模式: Ⅰ
关于 Panel 工作文件; Ⅱ
关于 Pool 对象
数据的预处理 1
在EXCEL 文件中,将每个变量各年的原始数据按照年份顺序排成一列,称之为堆积数据(见表“汇总 0”)
2.输入截面单元的标识(表示地区的符号,前面加_;如:_HB、_NMG 等)
3.将数据表按照时间分类(即排序,见表“汇总”)
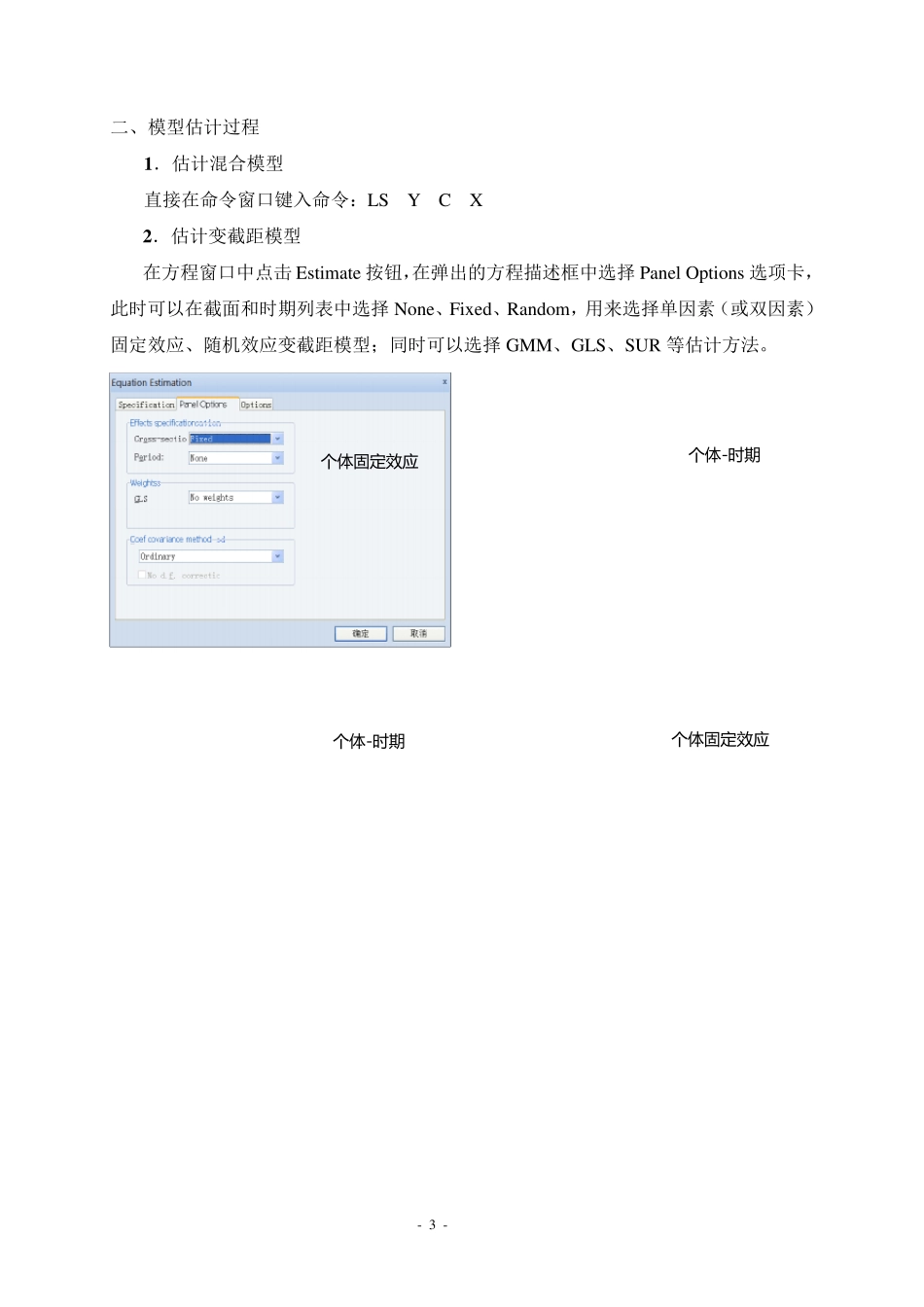
关于 Panel 工作文件的操作过程 案例 1:我国农村居民消费函数(2000-2010 年,27 个省市数据,工作文件:NXF) 一、输入数据 1、创建 Panel 工作文件 选择 File / New / Workfile,在出现的创建工作文件对话框中: (1)在文件结构类型中,选择“平衡面板(Balanced Panel)”; (2)输入起始、终止期,截面单元个数
- 2 - 2.更改截面标识(可以省略) 序列crossid 中是以数字1、2、…标记截面标识,为了便于区分,可以重新定义一个字符串序列
(1)点击object / New object,选择series Alpha 并输入序列名(设为dq); (2)双击dq 序列,在打开的序列窗口中粘贴截面标识的字符串序列; (3)双击工作文件窗口中的Range,在弹出的对话框中,将截面标识的的ID 序列改成新的标识序列:dq 3.输入数据 键入命令:DATA Y X,然后用复制+粘贴方式从Excel 文件中将各个变量的堆积数据(注意:数据事先要按照截面单元堆积,本例中是按照“地区”)复制到工作文件之中;此时工作文件中各个变量都是堆积数据
工 作 文 件 中 将 生 成 分 别 表 示 截面 标 识 和 时 期 标 识 的 两个序列: Crossid — 截面标识 - 3 - 二、模型估计过程 1 .估计混合模型 直