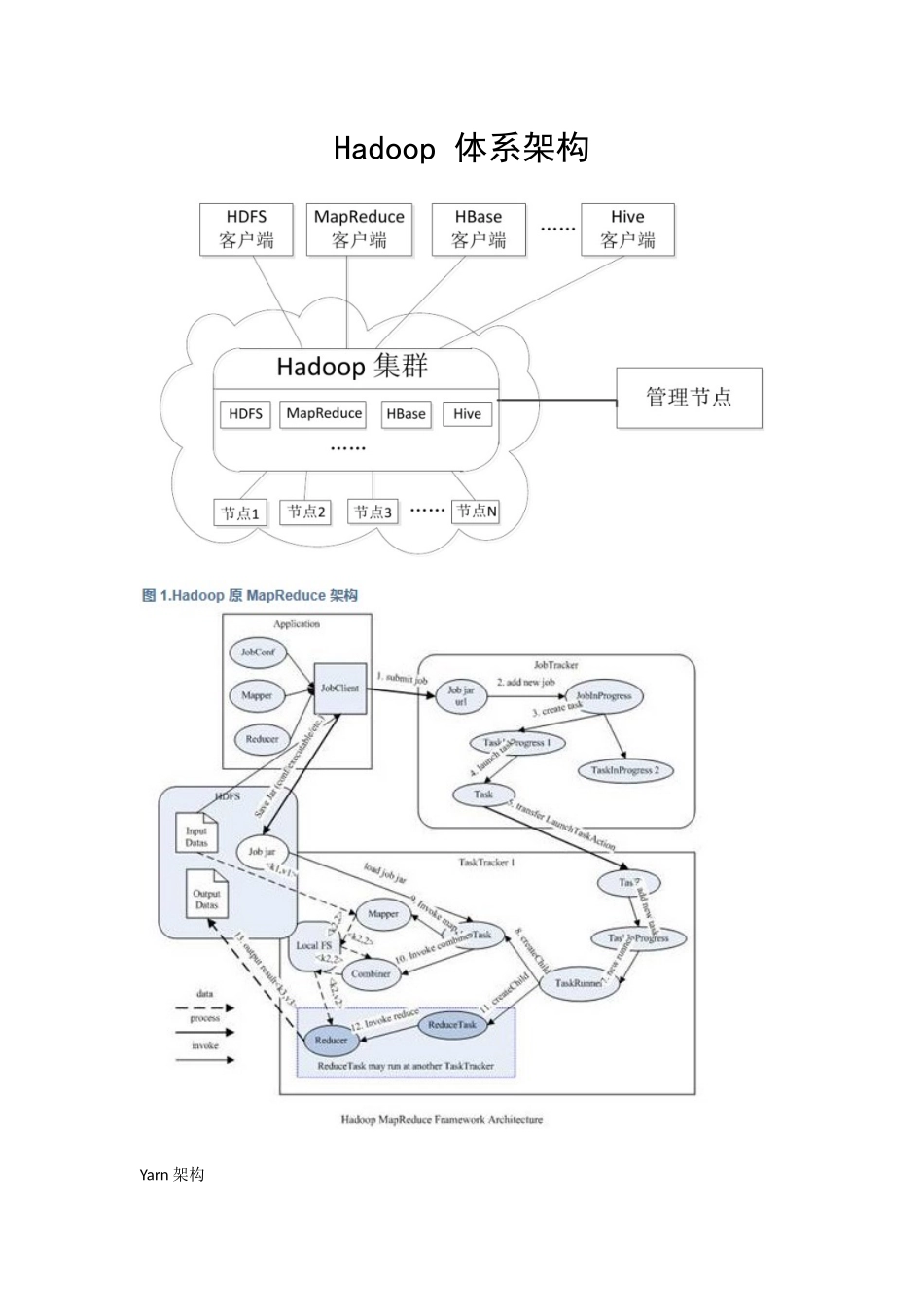
Hadoop 体系架构Yarn 架构Hadoop 和 MRv1 简单介绍Hadoop 集群可从单一节点(其中所有 Hadoop 实体都在同一个节点上运行)扩展到数千个节点(其中的功能分散在各个节点之间,以增加并行处理活动)
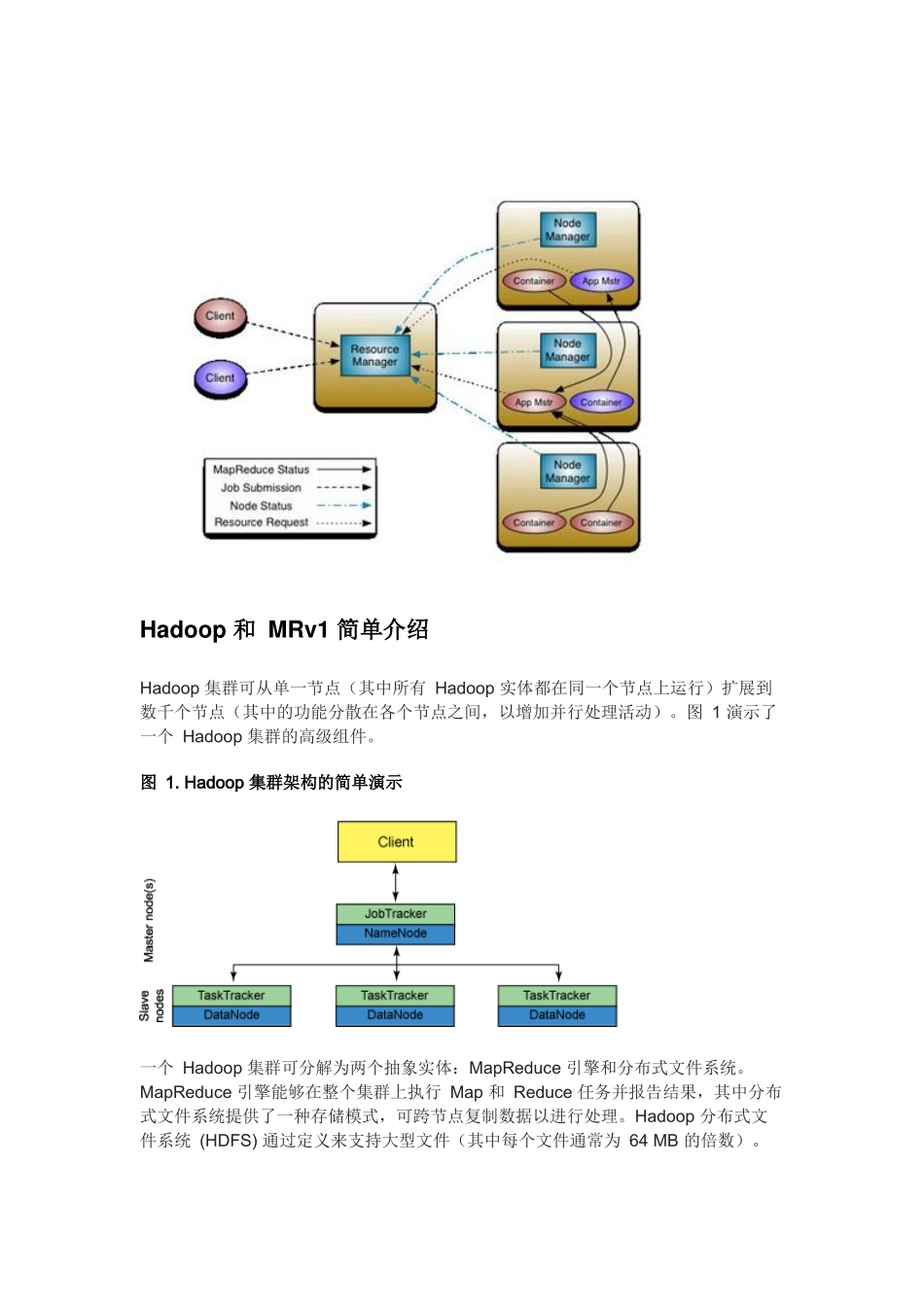
图 1 演示了一个 Hadoop 集群的高级组件
Hadoop 集群架构的简单演示一个 Hadoop 集群可分解为两个抽象实体:MapReduce 引擎和分布式文件系统
MapReduce 引擎能够在整个集群上执行 Map 和 Reduce 任务并报告结果,其中分布式文件系统提供了一种存储模式,可跨节点复制数据以进行处理
Hadoop 分布式文件系统 (HDFS) 通过定义来支持大型文件(其中每个文件通常为 64 MB 的倍数)
当一个客户端向一个 Hadoop 集群发出一个请求时,此请求由 JobTracker 管理
JobTracker 与 NameNode 联合将工作分发到离它所处理的数据尽可能近的位置
NameNode 是文件系统的主系统,提供元数据服务来执行数据分发和复制
JobTracker 将 Map 和 Reduce 任务安排到一个或多个 TaskTracker 上的可用插槽中
TaskTracker 与 DataNode(分布式文件系统)一起对来自 DataNode 的数据执行 Map 和 Reduce 任务
当 Map 和 Reduce 任务完成时,TaskTracker 会告知 JobTracker,后者确定所有任务何时完成并最终告知客户作业已完成
InfoSphere BigInsights Quick Start EditionInfoSphere BigInsights Quick Start Edition 是 IBM 基于 Hadoop 的产品 InfoSphere BigInsights 的一个免费可下载版本