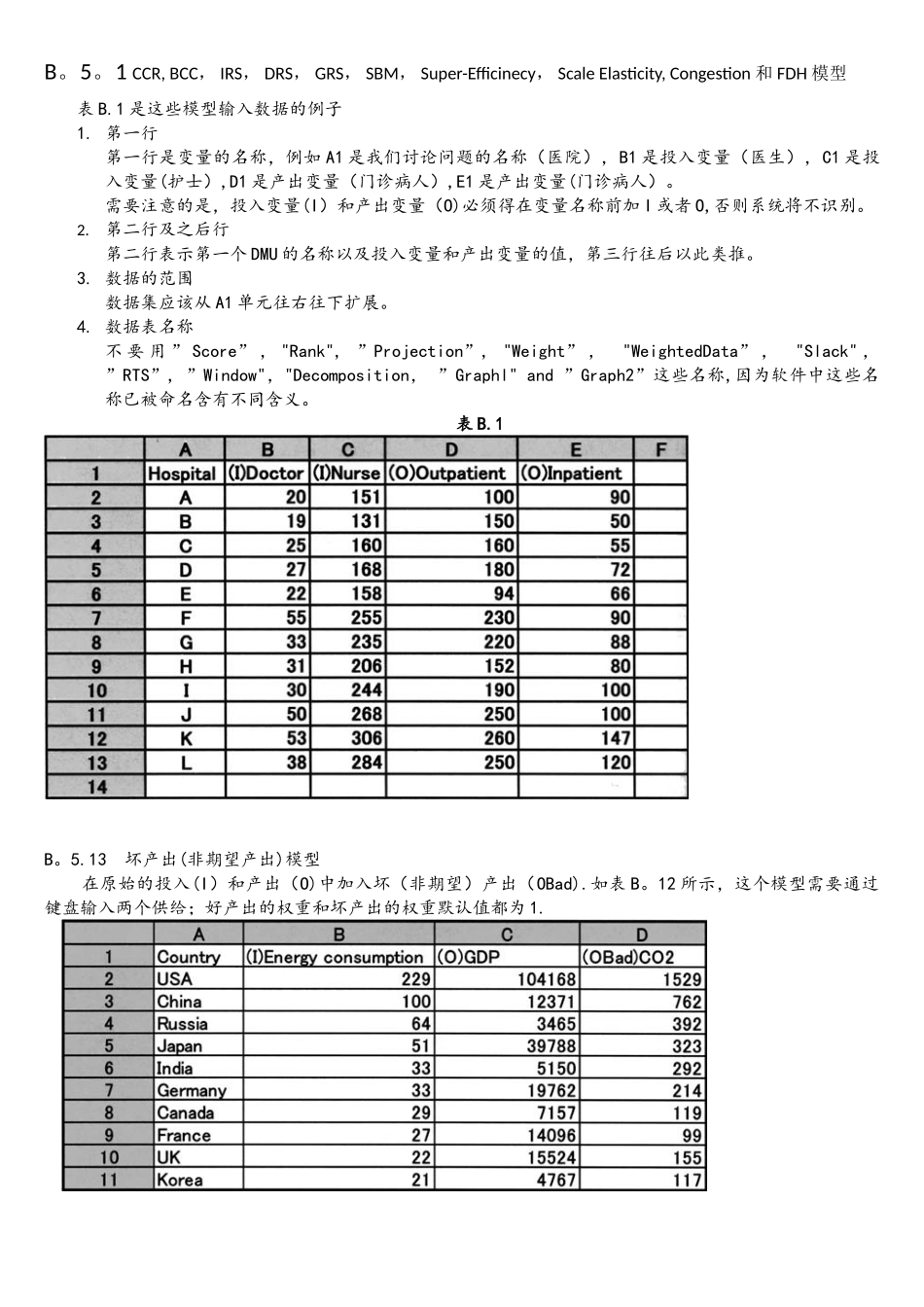
1 CCR, BCC, IRS, DRS, GRS, SBM, Super-Efficinecy, Scale Elasticity, Congestion 和 FDH 模型表 B
1 是这些模型输入数据的例子1
第一行第一行是变量的名称,例如 A1 是我们讨论问题的名称(医院),B1 是投入变量(医生),C1 是投入变量(护士),D1 是产出变量(门诊病人),E1 是产出变量(门诊病人)
需要注意的是,投入变量(I)和产出变量(O)必须得在变量名称前加 I 或者 O,否则系统将不识别
第二行及之后行第二行表示第一个 DMU 的名称以及投入变量和产出变量的值,第三行往后以此类推
数据的范围数据集应该从 A1 单元往右往下扩展
数据表名称不 要 用 ” Score” , "Rank", ”Projection”, "Weight” , "WeightedData” , "Slack" , ”RTS”, ”Window","Decomposition, ”Graphl" and ”Graph2”这些名称,因为软件中这些名称已被命名含有不同含义
13 坏产出(非期望产出)模型 在原始的投入(I)和产出(O)中加入坏(非期望)产出(OBad)
12 所示,这个模型需要通过键盘输入两个供给;好产出的权重和坏产出的权重默认值都为 1