无源领域自适应:Source Hypothesis Transfer for Unsupervised Domain Adaptation Do We Really Need to Access the Source Data
Source Hypothesis Transfer for Unsupervised Domain Adaptation Introduction 这是无源领域自适应的第一篇论文,之前的领域自适应往往是利用源域模型、源域数据进行迁移
考虑到源域数据的隐私性以及数据的庞大,作者创造性地提出了一种不借助源域数据,只利用从源域上训练出的模型向目标域进行迁移的方法——Source HypOthesis Transfer (SHOT)
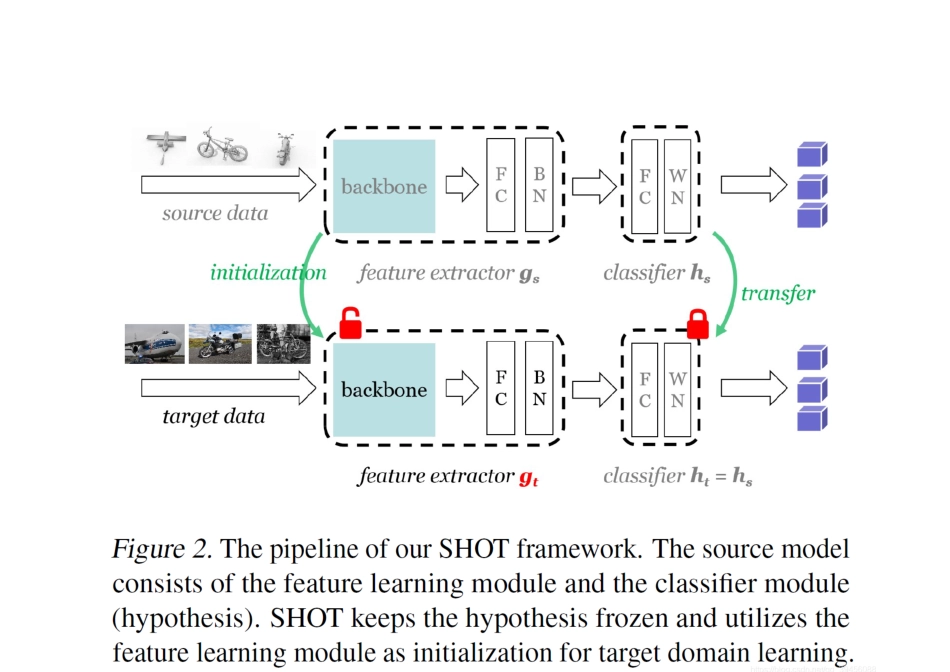
Method 上图是这篇论文提出的整体框架(SHOT),作者的思路很简单,首先利用源域数据有监督地训练出一个模型,然后利用源域模型初始化目标域模型,最后利用目标域数据训练该模型,完成迁移
在整个过程中,模型的分类器(图中的 classifier)是固定不动的,也就是不参与训练,直接使用源域训练出来的分类器,我们只需重新训练特征提取器(feature extractor),使其与目标域数据适配
Source Model Generation 这部分是源域模型的训练,利用卷积神经网络训练一个分类器
损失函数是交叉熵损失函数,不过作者为了提高模型分类的准确性,在损失函数中使用了标签平滑(label smoothing),训练源域模型的损失函数如下所示: SHOT-IM 这部分作者提出了一个信息最大化(Information Maximization)的方法进行从目标域到源域的对齐,即让目标域数据的特征和源域有着尽可能相似的分布
作者有着两方面的思考: 1、如果目标域数据和源域数据的差异被消除了,那么目标域数据的输出也应该和源域