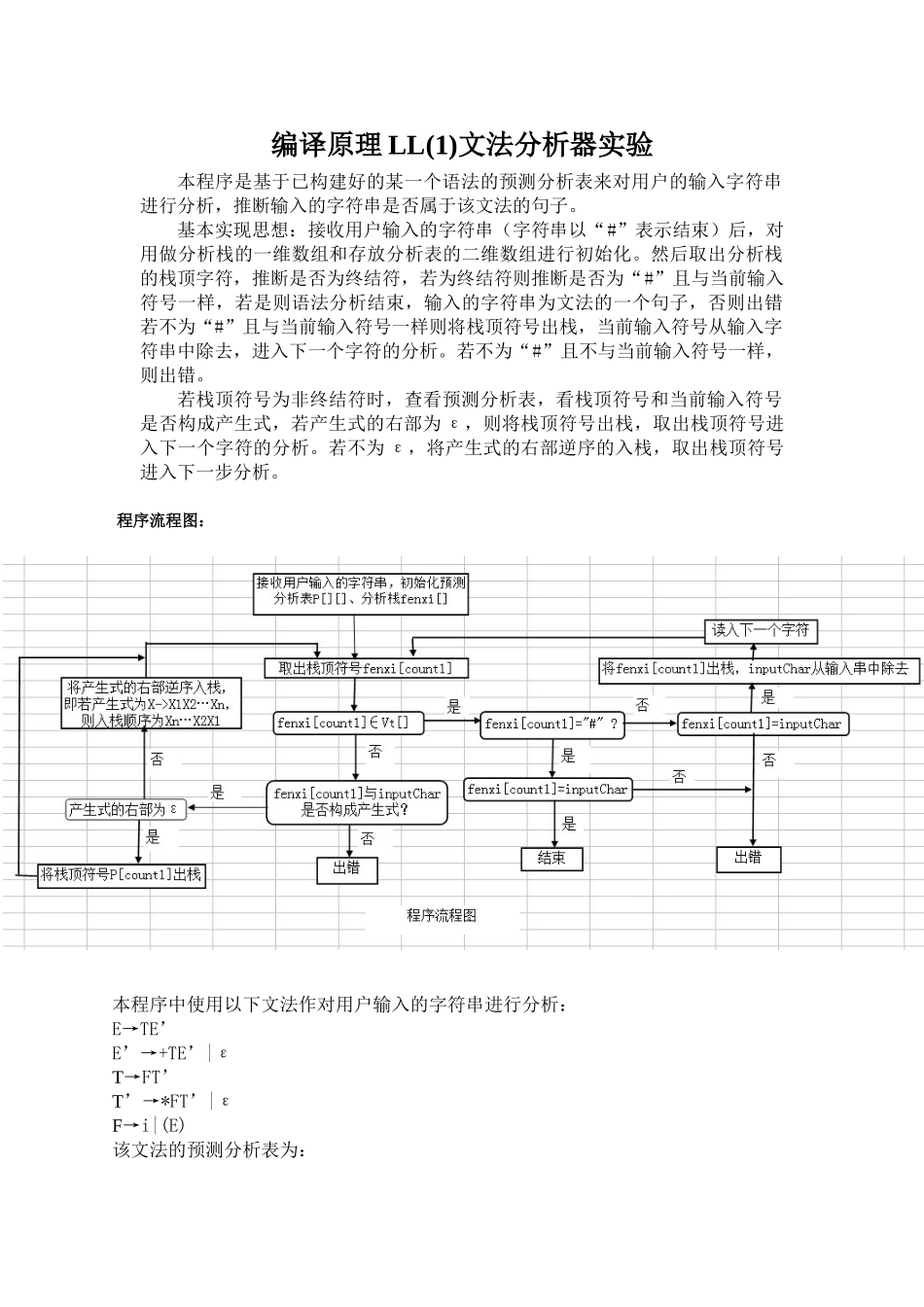
编译原理 LL(1)文法分析器实验本程序是基于已构建好的某一个语法的预测分析表来对用户的输入字符串进行分析,推断输入的字符串是否属于该文法的句子
基本实现思想:接收用户输入的字符串(字符串以“#”表示结束)后,对用做分析栈的一维数组和存放分析表的二维数组进行初始化
然后取出分析栈的栈顶字符,推断是否为终结符,若为终结符则推断是否为“#”且与当前输入符号一样,若是则语法分析结束,输入的字符串为文法的一个句子,否则出错若不为“#”且与当前输入符号一样则将栈顶符号出栈,当前输入符号从输入字符串中除去,进入下一个字符的分析
若不为“#”且不与当前输入符号一样,则出错
若栈顶符号为非终结符时,查看预测分析表,看栈顶符号和当前输入符号是否构成产生式,若产生式的右部为 ε,则将栈顶符号出栈,取出栈顶符号进入下一个字符的分析
若不为 ε,将产生式的右部逆序的入栈,取出栈顶符号进入下一步分析
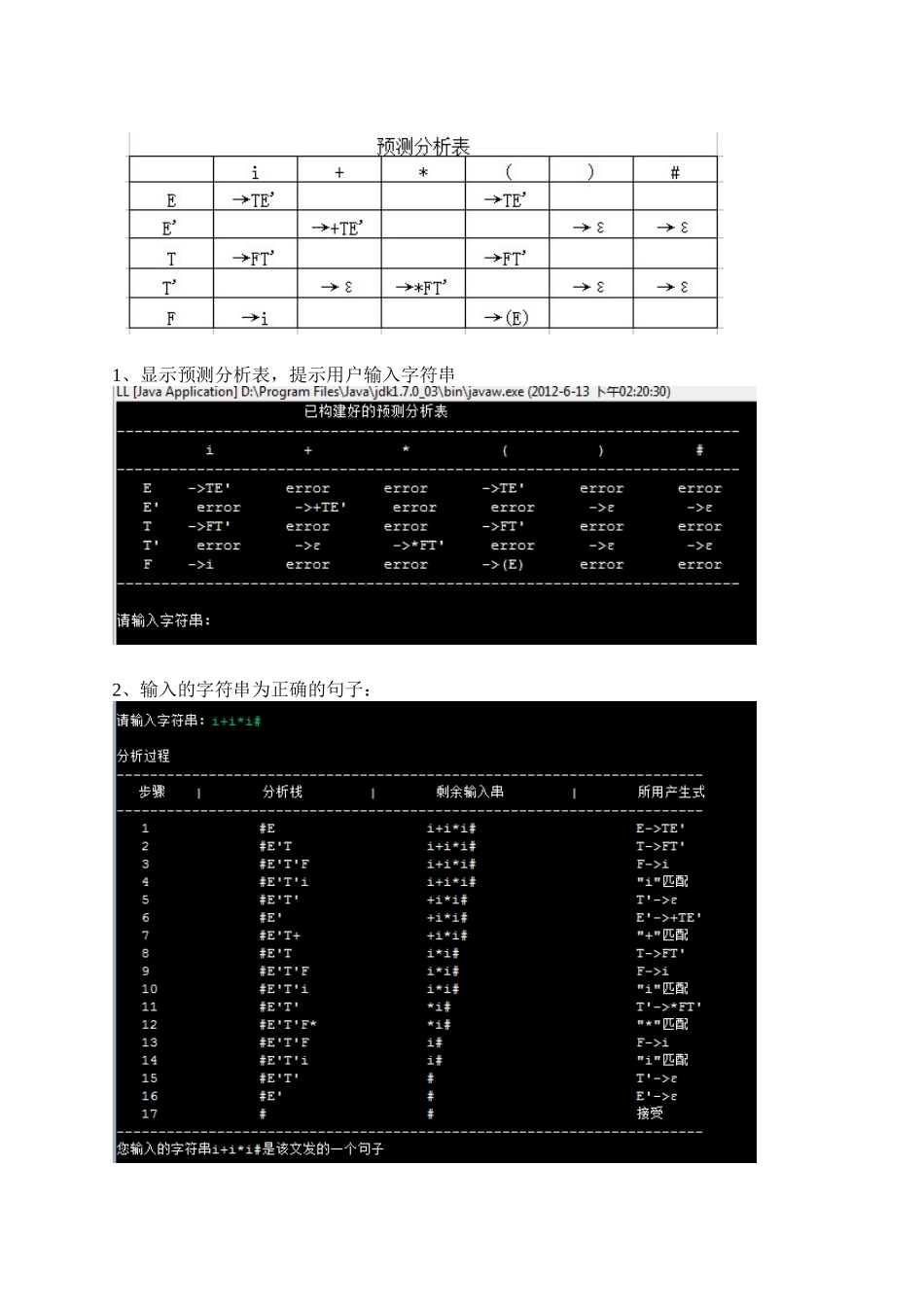
程序流程图:本程序中使用以下文法作对用户输入的字符串进行分析:E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→i|(E)该文法的预测分析表为:1、显示预测分析表,提示用户输入字符串2、输入的字符串为正确的句子:3、输入的字符串中包含了不属于终结符集的字符4、输入的字符串不是该文法能推导出来的句子程序代码:package zhuangms
com;import java
*;public class LL {String Vn[] = { "E", "E'", "T", "T'", "F" }; // 非终结符集String Vt[] = { "i", "+", "*", "(", ")", "#" }; // 终结符集String P[][] = new String[5][6]; // 预测分析表String fenxi[] ; // 分析栈int count =