几种网络视频编码技术的分析、比较与发展摘要:本文主要介绍了MPEG,H
264,AVS等3种主流网络视频编码标准
并从编码的关键技术,创新改进等方面对这三种标准进行了分析比较
以期在未来的实际应用中,能够更好的做出选择
1引言网络技术的快速发展,高速数据传输以及大数据容量的传输,而短时间内无法突破硬件存储容量的限制,推动了网络视频编码技术的革新、发展
通过各种网络视频编码标准的算法优化,给人们提供了一个良好的视听娱乐体验,本文将从目前主流的几种标准,即MPEG-4,H
264以及AVS对比分析各自的关键技术特点以及创新优势
2几种主流标准介绍2
1MPEG-4标准MPEG(MovingPicturesExpertsGroup)即动态图像专家组是目前影响最大、应用最广的多媒体技术标准
他包括MPEG-1、MPEG-2、MPEG-4、MPEG-21等众多分支[1]
每一个分支都侧重于不同的应用,本文主要针对MPEG-4标准进行阐述
264标准H
264是ITU-T和ISO/IEC联合制定的一种视频编码标准,他具有高效的编码标准和易于网络传输的特点,H
264标准同时定义了四个档次,即基本档次,主档次、扩展档次和高级档次,以满足视频电话、视频会议、视频存储、视频广播等众多领域的应用
3AVS标准AVS(AudioVideocodingStandard,音视频编码标准)是《信息技术先进音视频编码》系列标准的简称,是我国具备自主知识产权的第二代信源编码标准,也是数字音视频产业的共性基础标准
3一般性视频编码结构介绍3
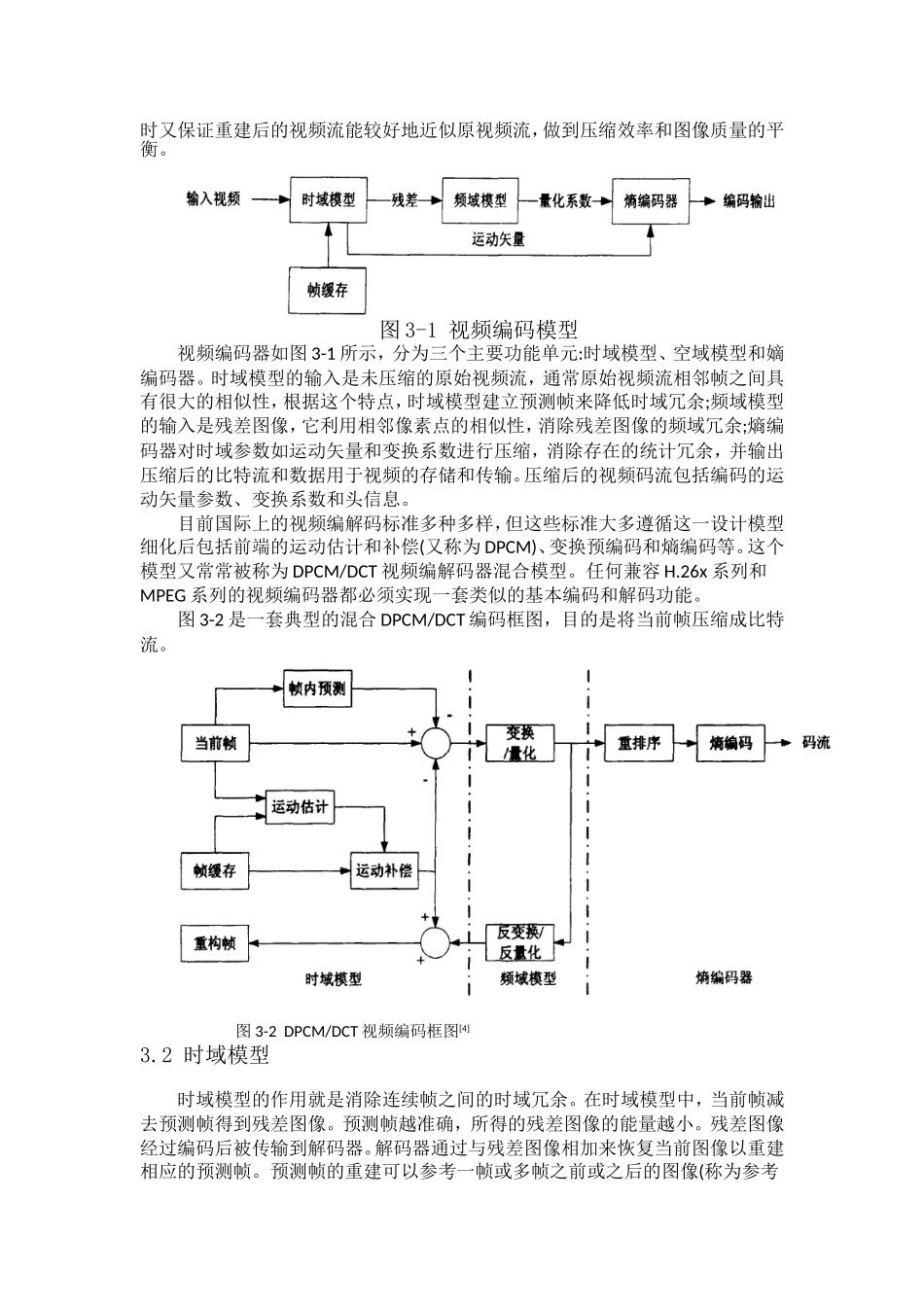
1视频编码结构介绍视频编码理论和其他科学研究一样,离不开数学模型的支撑
视频编码器采用模型来描述一个视频流
这种模型使得压缩数据尽可能占用最少的bit数,同时又保证重建后的视频流能较好地近似原视频流,做到压缩效率和图像质量的平衡
图3-1视频编码模型视频编