1回归分析的基本思想及其初步应用我们知道,函数关系是一种确定性关系,而相关关系是一种非确定性关系
回归分析(regressionanalysis)是对具有相关关系的两个变量进行统计分析的一种常用方法
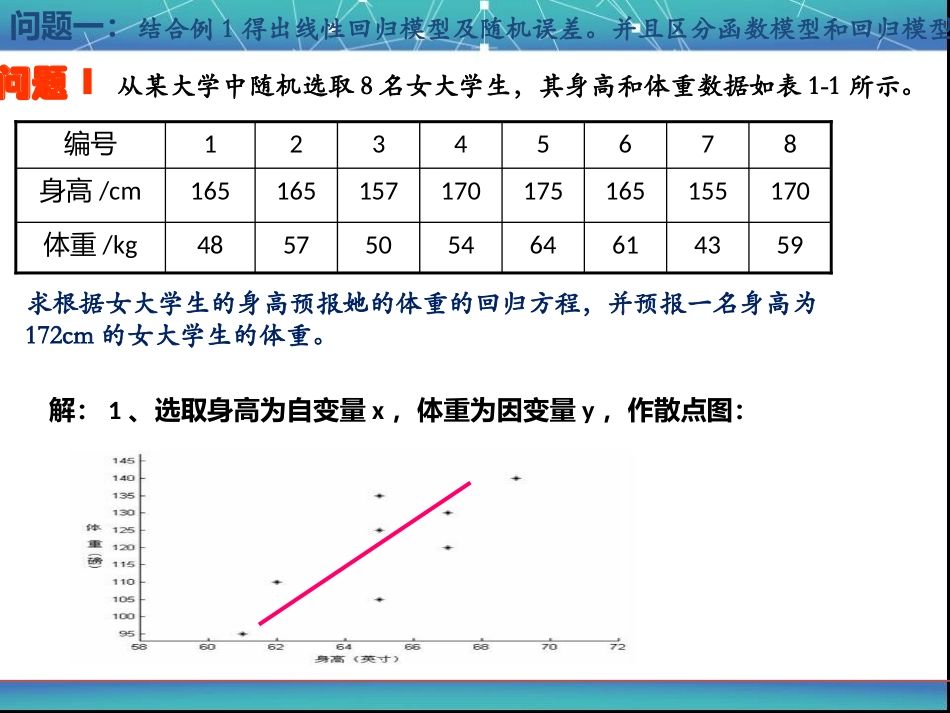
下面我们通过具体问题,进一步学习回归分析的基本思想及其应用于问题1从某大学中随机选取8名女大学生,其身高和体重数据如表1-1所示
5943616454505748体重/kg170155165175170157165165身高/cm87654321编号求根据女大学生的身高预报她的体重的回归方程,并预报一名身高为172cm的女大学生的体重
问题一:结合例1得出线性回归模型及随机误差
并且区分函数模型和回归模型
解:1、选取身高为自变量x,体重为因变量y,作散点图:2
回归方程:172
0ˆxyˆ学身高172cm女大生体重y=0
849×172-85
712=60
316(kg)探究:身高为172cm的女大学生的体重一定是60
316kg吗
如果不是,你能解析一下原因吗
答:用这个回归方程不能给出每个身高为172cm的女大学生的体重的预测值,只能给出她们平均体重的估计值
由于所有的样本点不共线,而只是散布在某一直线的附近,所以身高和体重的关系可以用线性回归模型来表示:其中a和b为模型的未知参数,e称为随机误差
eabxy函数模型与“回归模型”的关系函数模型:因变量y完全由自变量x确定回归模型:预报变量y完全由解释变量x和随机误差e确定注:e产生的主要原因:(1)所用确定性函数不恰当;(2)忽略了某些因素的影响;(3)观测误差
思考:产生随机误差项e的原因是什么
问题二:在线性回归模型中,e是用bx+a预报真实值y的随机误差,它是一个不可观测的量,那么应如何研究随机误差呢
,,1,2,
iiiiiiiiybxaineyyybxaine