原创ICDA数据分析研究院,转载需授权介绍如果说在机器学习领域有哪个优化算法最广为认知,用途最广,非梯度下降算法莫属
梯度下降算法是一种非常经典的求极小值的算法,比如在线性回归里我们可以用最小二乘法去解析最优解,但是其中会涉及到对矩阵求逆,由于多重共线性问题的存在是很让人难受的,无论进行L1正则化的Lasso回归还是L2正则化的岭回归,其实并不让人满意,因为它们的产生是为了修复此漏洞,而不是为了提升模型效果,甚至使模型效果下降
但是换一种思路,比如用梯度下降算法去优化线性回归的损失函数,完全就可以不用考虑多重共线性带来的问题
其实不仅是线性回归,逻辑回归同样是可以用梯度下降进行优化,因为这两个算法的损失函数都是严格意义上的凸函数,即存在全局唯一极小值,较小的学习率和足够的迭代次数一定可以达到最小值附近,满足精度要求是完全没有问题的
并且随着特征数目的增多(列如100000),梯度下降的效率将远高于去解析标准方程的逆矩阵
神经网络中的后向传播算法其实就是在进行梯度下降,GDBT(梯度提升树)每增加一个弱学习器(CART回归树)近似于进行一次梯度下降,因为每一棵回归树的目的都是去拟合此时损失函数的负梯度,这也可以说明为什么GDBT往往没XGBoost的效率高,因为它没办法拟合真正的负梯度,而Xgboost的每增加的一个弱学习器是使得损失函数下降最快的解析解
总之梯度下降算法的用处十分广泛,我们有必要对它进行更加深入的理解
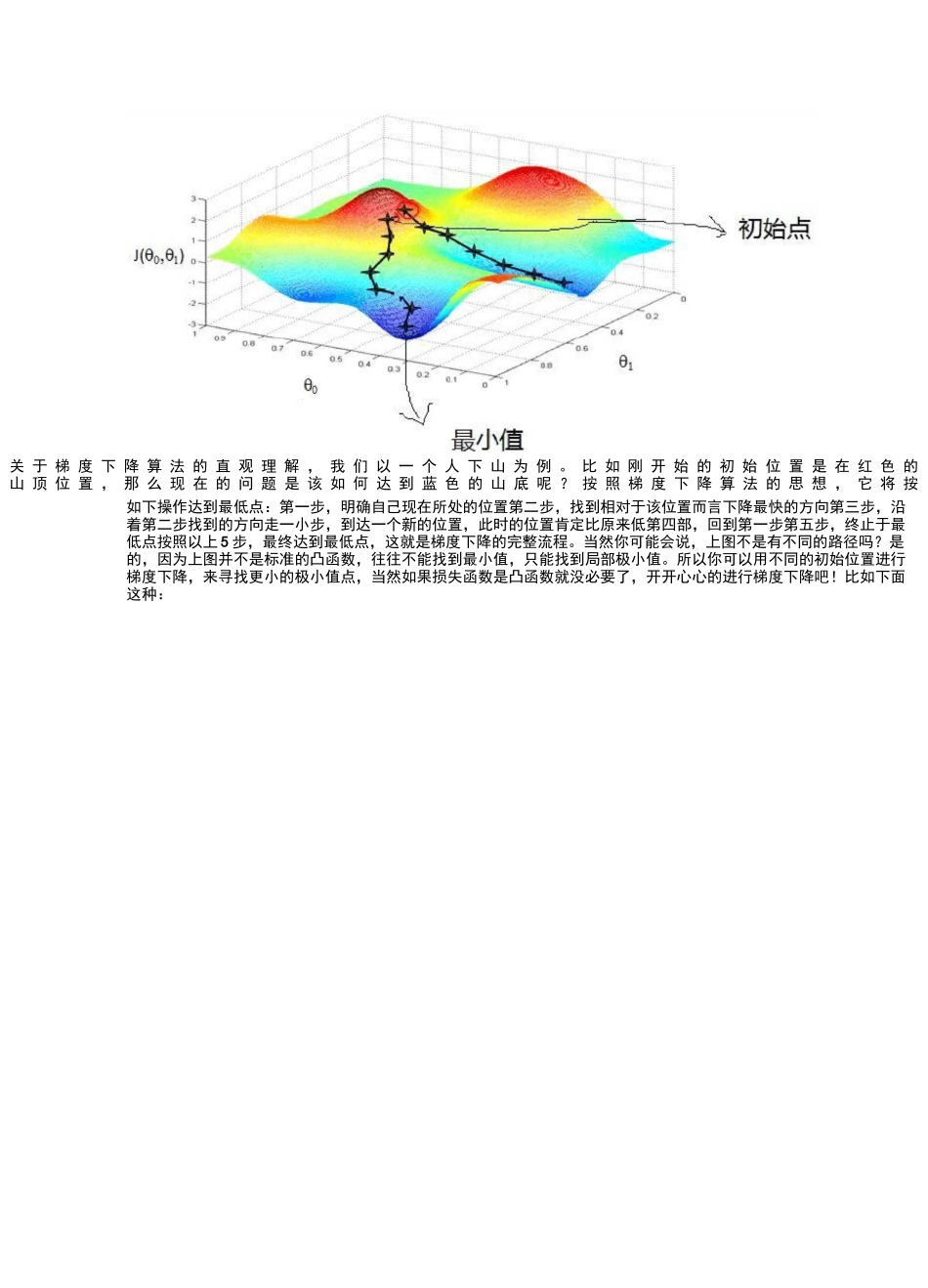
关于梯度下降算法的直观理解关于梯度下降算法的直观理解,我们以一个人下山为例
比如刚开始的初始位置是在红色的山顶位置,那么现在的问题是该如何达到蓝色的山底呢
按照梯度下降算法的思想,它将按如下操作达到最低点:第一步,明确自己现在所处的位置第二步,找到相对于该位置而言下降最快的方向第三步,沿着第二步找到的方向走一小步,到达一个新的位置,此时的位置肯定比原来低第四部