最近在跟台大的这个课程,觉得不错, 想把学习笔记发出来跟大家分享下,有错误希望大家指正
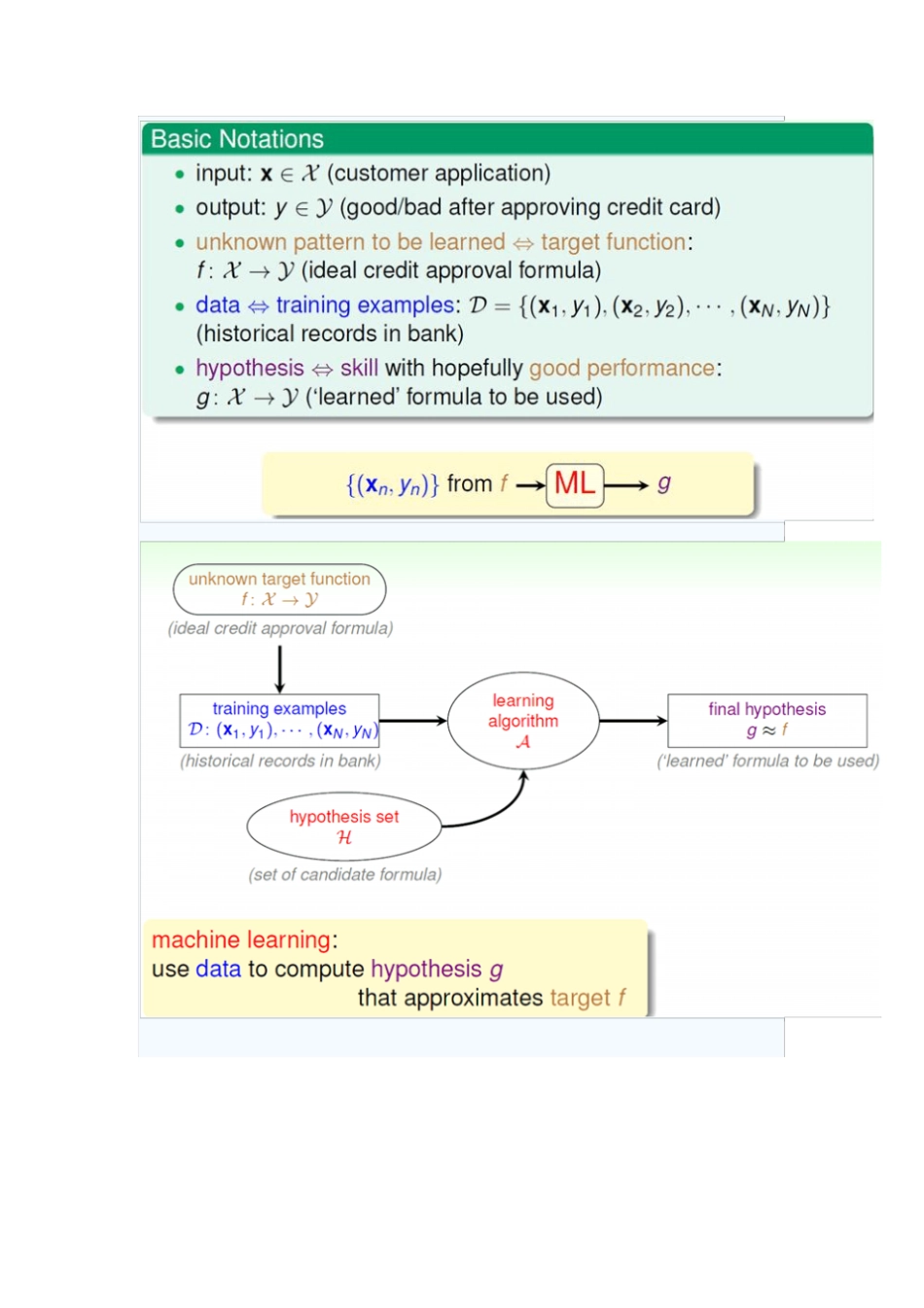
一机器学习是什么
感觉和 Tom M
Mitchell的定义几乎一致,A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
简而言之,就是我们想要机器在某些方面有提高(如搜索排名的质量,即NDCG 提高),就给机器一些数据(用户的点击数据等各种)然后让机器获得某些经验( Learning to rank的一种模型,也就是数学公式)
这里有点需要强调,那就是提高指标,必须要有某种指标可以量化这种提高,这点还是很关键的,工业界做机器学习,首先关注data ,其次就是有无成型的 measurement ,可以使 Precision/Recall ,也可以是 NDCG 等
二什么时候可以用机器学习
其实就三要素:1
有规律可以学习;2
编程很难做到;3
有能够学习到规律的数据;编程很难做到可以有多种,大部分原因是系统太复杂,很难用 Rule-based的东西去解决,例如搜索排名,现在影响排名的因素有超多几百种,不可能去想出这些因素的规则,因此,这时候用机器学习就是恰到好处
特别是移动互联网的今天,用户更容易接触互联网,产生的数据越来越多,那么要找到某些不容易实现的规律,用机器学习就是很好的了,这也是为啥机器学习这么火,其实我学机器学习不仅仅是一种投资(肯定它未来的发展前途),我想做的事情还有一点,就是通过它更深刻的理解人脑的学习过程,提高自己的学习效率和思维