一个汉英机器翻译系统的计算模型与语言模型* 刘 群+ 詹卫东++ 常宝宝++ 刘颖+(+中国科学院计算技术讨论所二室 北京 100080)(++北京大学计算语言学讨论所 北京 100871)摘要:本文介绍我们所设计并实现的一个汉英机器翻译系统
在概要介绍本系统的主要目标和设计原则的基础上,着重说明系统的计算模型和语言模型,最后给出实验结果和进一步的打算
关键词:自然语言处理 机器翻译 中文信息处理一、引言我国的机器翻译讨论近年来取得了很大的进展
特别是英汉机器翻译系统的研制已经取得了较大的成功,达到了初步有用的阶段
相对而言,汉英机器翻译的讨论却进展比较缓慢,离有用化还有相当的距离[1]
我们的目的是利用目前最新的计算机软件技术、相对成熟的机器翻译方法和先进的汉语语法理论,构造一个初步有用的汉英机器翻译系统
本文将对我们所开发的系统所采纳的计算模型和语言模型作一个总体性的介绍,而不涉及过多的细节
下面我们简要介绍一下本系统的几个主要设计原则:⑴ 采纳成熟的技术我们的目的是构造一个真正有用的汉英机器翻译系统,因而在可供选择的若干技术路线面前,我们将尽量选用比较成熟的技术,而在现有技术难以解决问题时再尝试一些新技术
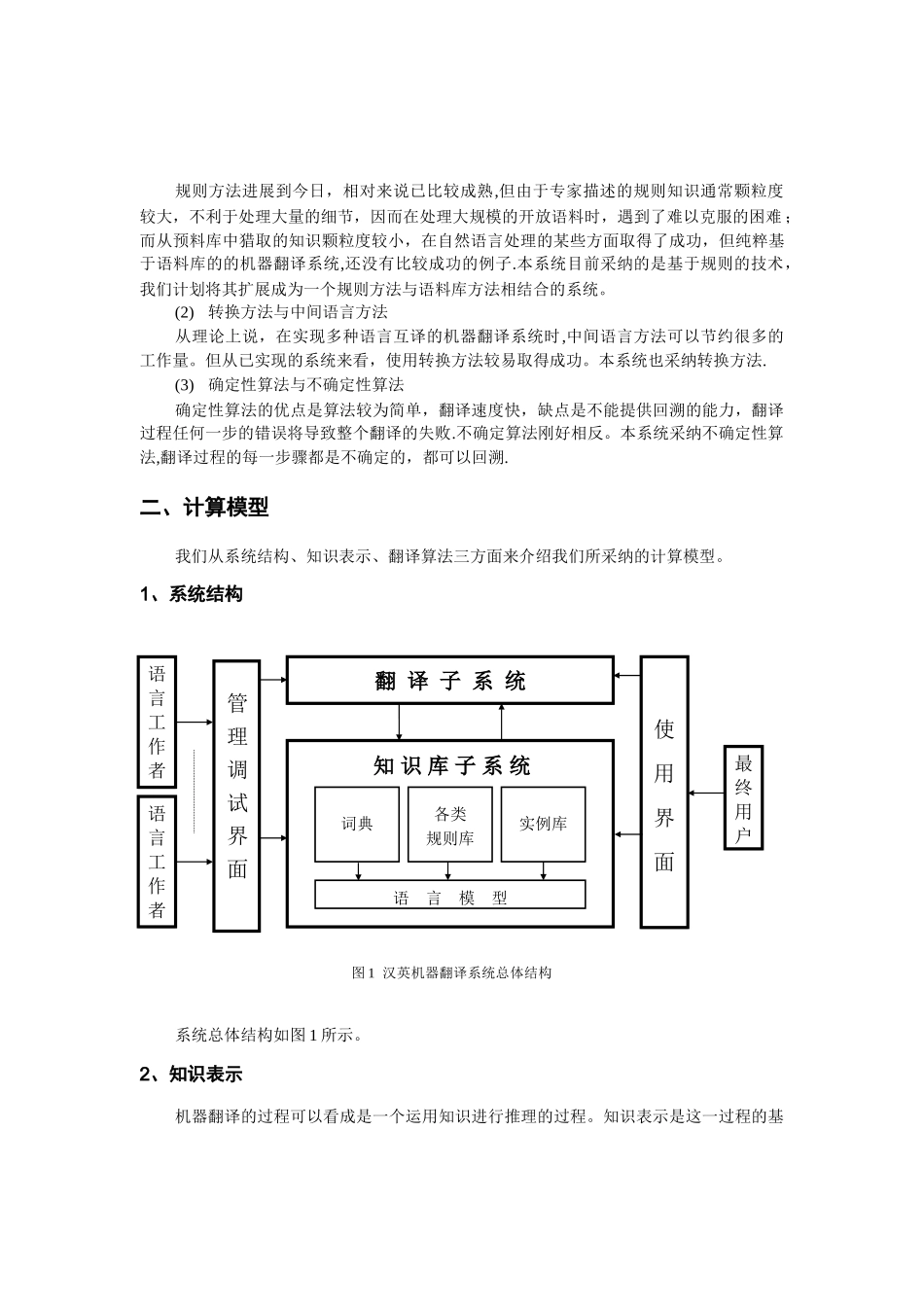
⑵ 开放的体系结构开放的体系结构主要体现在系统的实现上所采纳的软件构件技术 [8]
整个系统采纳一些相对独立的软件构件组成,因而可以方便地对系统进行修改、维护和扩充
翻译的过程严格根据独立分析、独立生成的原则进行组织,每一阶段的算法相互独立,对其中一个阶段算法的修改不会对其他算法造成影响
⑶ 方便的调试环境本系统强调为语言工作者提供一个方便的调试环境
系统提供多窗口图形界面的知识库调试工具,支持课题组中多人同时通过网络对一个知识库进行操作
提供对翻译过程直观显示,用户可以清楚地看到翻译过程的每一步操作
提供翻译出错原因查找机制,用户可以轻松确定翻译出错的位置