1背景说到相关系数,学过生物统计的人应该不会太陌生
随着基因芯片和高通量测序技术的发展,相关系数在生物数据统计中的应用越来越普遍
例如,通过计算不同基因表达量的相关系数,来构建基因共表达网络
大部分基因网络分析的方法,都与基因间表达量相关系数的计算相关(即使是复杂一点的算法,相关系数的计算也可能是算法的基础部分)所以理解相关系数,对分析生物学数据非常重要
2皮尔森相关2
1概念在所有相关系数的计算方法里面,最常见的就是皮尔森相关
皮尔森相关百度百科解释:皮尔森相关系数(Pearsoncorrelationcoefficient)也称皮尔森积差相关系数(Pearsonproduct-momentcorrelationcoefficient),是一种线性相关系数
皮尔森相关系数是用来反映两个变量线性相关程度的统计量
相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值
r描述的是两个变量间线性相关强弱的程度
r的绝对值越大表明相关性越强
2数据测试公式是抽象的,我们利用几组值就可以更好理解相关系数的意义
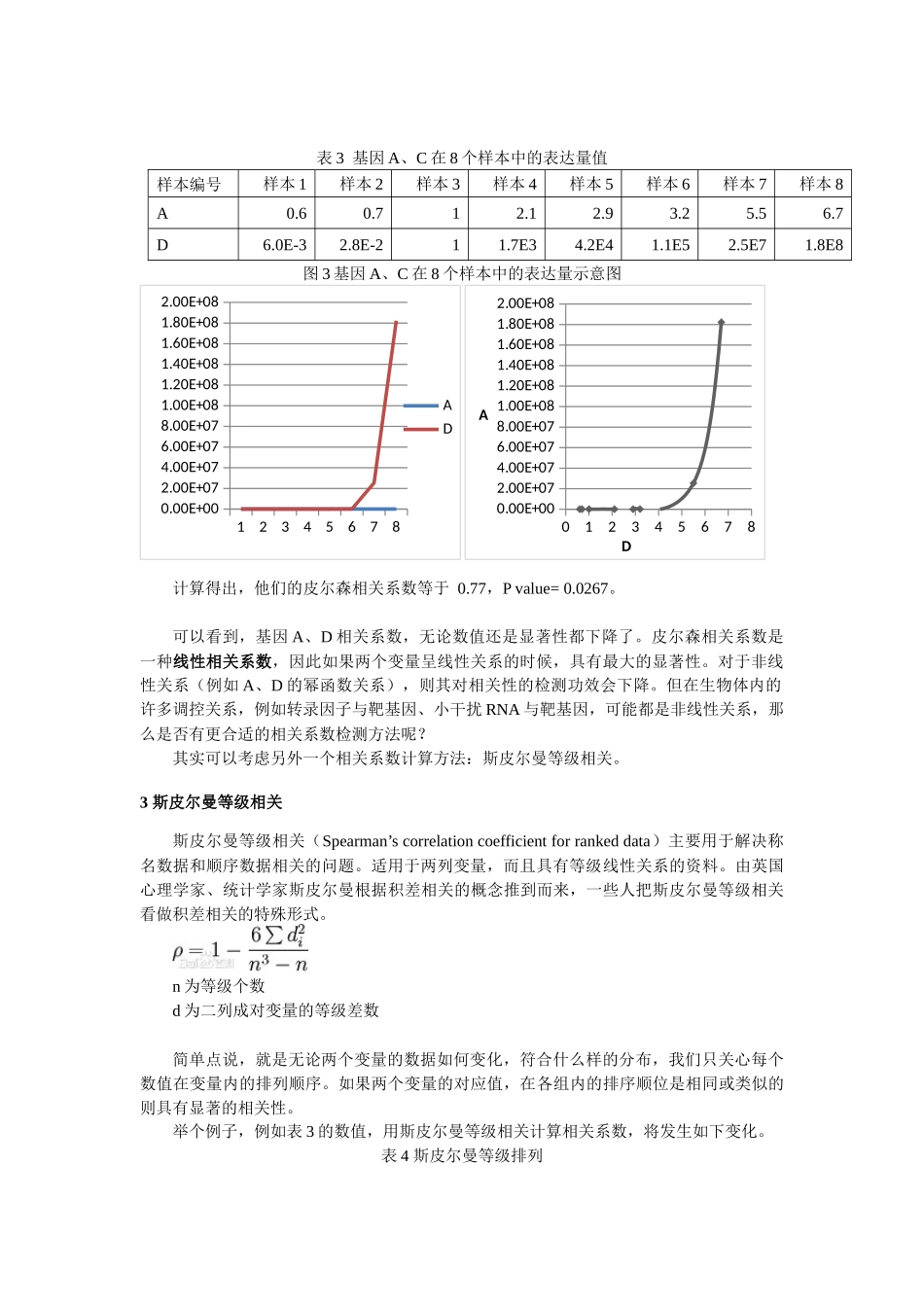
从皮尔森相关系数定义来看,如果两个基因的表达量呈线性关系(数学上,线性相关指的是直线相关,指数幂函数、正弦函数等曲线相关不属于线性相关),那么两个基因表达量的就有显著的皮尔森相关系性
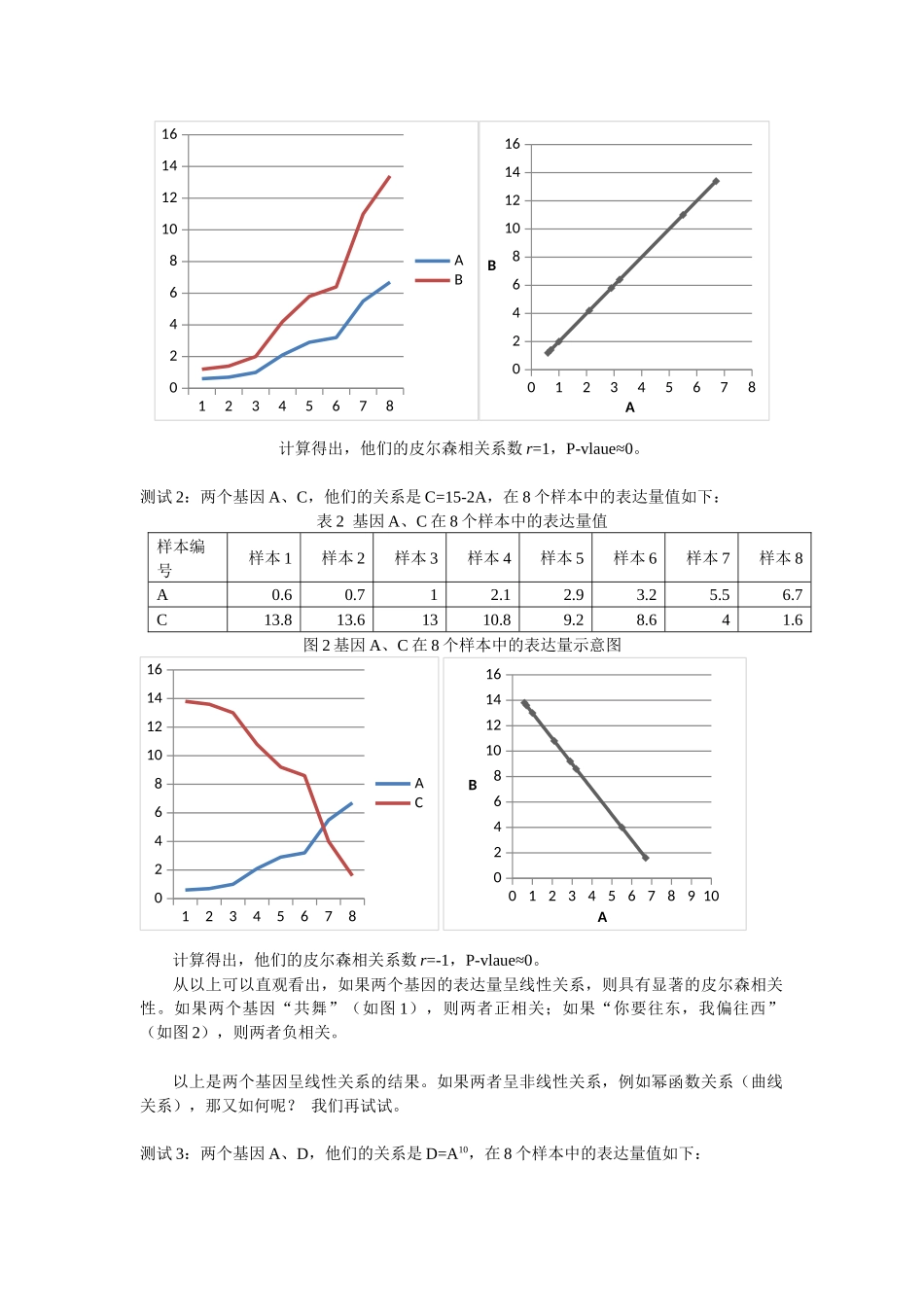
下面用几组模拟数值来测试一下:测试1:两个基因A、B,他们的表达量关系是B=2A,在8个样本中的表达量值如下:表1基因A、B在8个样本中的表达量值样本编号样本1样本2样本3样本4样本5样本6样本7样本8A0
4图1基因A、B在8个样本中的表达量示意图123456780246810121416AB0123456780246810121416AB计算得出,他们的皮尔森相关系数r=1,P-vlaue≈0