Python中文处理zhoo
xuan@gmail
com2011
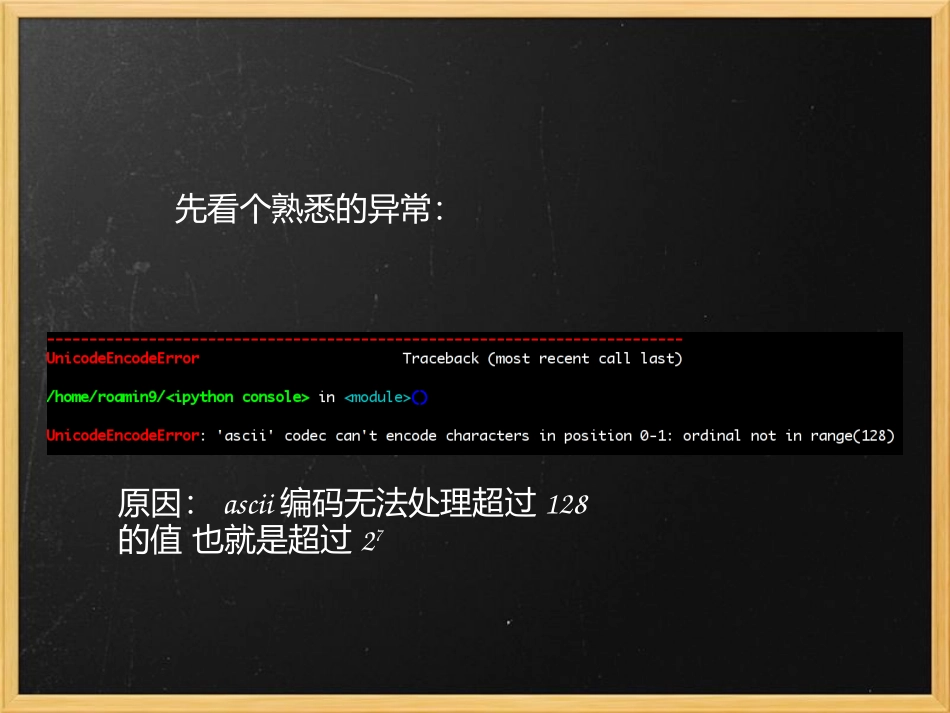
5先看个熟悉的异常:原因:ascii编码无法处理超过128的值也就是超过27ASCII编码:使用了7位来表示字符,所能表示的字符数量也就是0~127对于中文来说,远远不够于是
讲点ascii历史Unicode顺应而生
Unicodeisacomputingindustrystandardfortheconsistentencoding,representationandhandlingoftextexpressedinmostoftheworld'swritingsystems
--摘自wikipedia刚才那个太抽象哈unicode是个方便各种编码之间转换的标准,它可以包含世界上的所有字符codepoint,unicode标准定义了如何通过codepoint来表示字符
codepoint是个int型的值,用16位表示
形如U+897f,对应0x897f一个codepoint,也就相当与一个unicodecharacterunicodestring,也就是许多的codepoint连接在一起encode:把unicodestring转换为一系列的字节decode:把一系列的字节值转换为unicodestringgbk编码:使用了两个字节来表示一个字符utf-8编码:1,codepointis